









MySQL InnoDB 之 Buffer Pool
Buffer Pool 是innodb 缓存表数据及索引数据的主要内存空间,允许频繁访问的数据直接通过内存访问。在专用的服务器上,通常把物理内存的80%以上分派给buffer pool。可想而知,Buffer Pool 也是利用内存缓存来提高性能的关键,因此如何合理利用 Buffer Pool 使其更好的体现价值是一个重要的话题。但为了适用各种各样的场景,Innodb 为这些可能的性能影响点都提供了配置项,允许根据具体场景设定对应的参数值以达到最佳的性能效果。
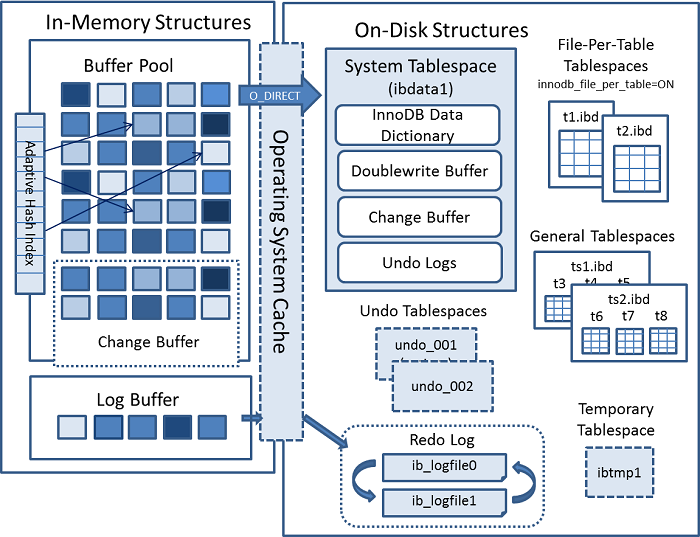
MySQL InnoDB 架构
MySQL Innodb 架构
- 1. In-Memory Structures
- 2. On-Disk Structures
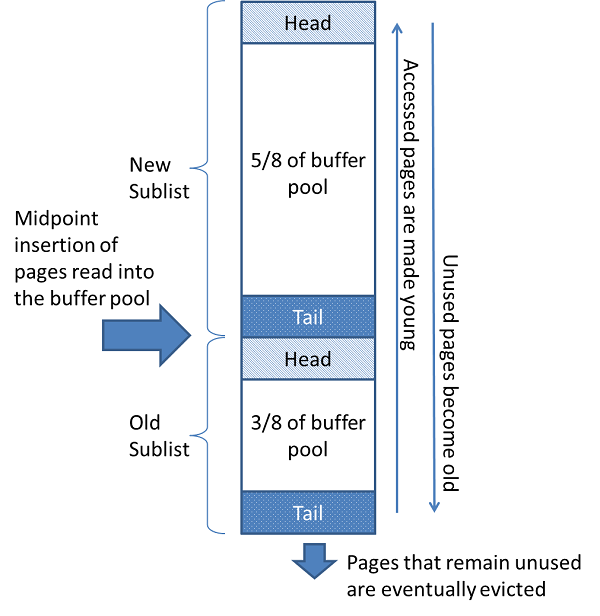
In-Memory Structures
1.Buffer Pool
Buffer Pool 是innodb 缓存表数据及索引数据的主要内存空间,允许频繁访问的数据直接通过内存访问。在专用的服务器上,通常把物理内存的80%以上分派给buffer pool。
为了提高大容量读操作的效率,buffer pool 被分成了可以保存多行(mutiple row)的页(page)。为了缓存的有效管理,buffer pool 以 page 链表(linked list)的形式实现,使用一种类似LRU的实现,最近很少访问的页将从缓存中删除。
了解如何利用 buffer pool 使频繁访问的数据保持内存中,是Mysql 调优很重要的一方面。
Logstash 聚合插件 aggregate filter 的使用心得
在ELK常规的使用模式下,我们收集Nginx访问日志是按照单行进行的。这样比如说有10个用户请求,对应在ElasticSearch中就是10条记录(也称为10个document)。下面将分别描述此种收集方法的优缺点。
首先,这样的收集方式非常利于按照指定字段去搜索,并根据匹配的记录去查看其它字段的信息。比如统计客户端IP为 127.0.0.1 的请求有多少,使用IPhone 手机的请求有多少。当出现 499 、502 状态码时,看看这些请求的URL是什么,然后快速定位问题。这些方法都是非常非常实用而且好用的。
其次,除了上面的这些需求之外,我们还想要制作统计图,比如统计按时间范围统计总请求数,4xx 数量,5xx数量,响应时间超过 500ms的请求数,输出的字节数量,平均响应时间。特别是最后2项,时间范围跨度越长,数据量越大,计算时间就越长。据我们实际使用中的数据量,单个索引,每天 3亿的文档数量,对应就有120G左右的数据,在单个dashboard中同时展示上面的几种图标,如果时间跨度超过1小时,页面加载时间就会超过 2s 。而kibana又提供了自动刷新功能,这样如果有多个人同时使用 elasticsearch就会咔咔的慢。
全局唯一 ID 如何生成?
ID 生成,提到这个词可能最快想到的就是 MySQL 数据库 insert 时的自增ID。当业务访问量剧增,单表的 insert 性能遇到瓶颈时,我们就必须使用分库、分表机制来分担这些负载到单个MySQL表上,但是我们都知道MySQL表中的主键自增是基于单表的,如果2个表中有2个自增字段,那他们默认都是从1开始自增,每次增加步长为1,那么这在有些业务场景下就不满足需求了。比如订单系统,必须要保证订单ID是全局唯一的,也就是所有订单库、表中的ID不能相同,不能用2个相同的订单ID代表不同的订单信息。
那么,我们有没有办法来解决这个问题,那肯定是有的,我想所有的方案不外乎这3种,第一,直接使用MySQL来解决,第二,依赖其他中间件生成唯一 ID(比如 redis),第三,业务中使用算法实现唯一ID。我们接下来分别来阐述这3种不同的解决方案,及其对应的优缺点。
Redis Replication 实现原理
对于 Master/Slave 模式,在我们常用的Mysql中你一定有或多或少的了解,应该知道它的一些价值,比如灾备、读写分离。就灾备一项就足以使我们必须使用它,因为一旦服务器软硬件故障,可能造成数据永不可恢复。你可能会说,可以提前做好数据文件备份,但是要远比修改一个 IP 更加复杂与时间开销更大。在Master/Slave 模式下还可以结合LVS/Keepalived 实现故障自动转移,使其具体业务方无感知。
在 Redis 2.8 版本之前,Master/Slave 之前只支持全量同步(full resync),从 2.8版本开始支持了部分重同步(partial resynchronization),使得在短暂的网络中断恢复后,不需要进行全量数据同步,而是只同步最近新增的数据即可。那么如何理解这个“短暂”,其实是取决于配置参数与实际场景,下面将带大家一起抽丝剥茧,找出真相。
Javascript Ajax 跨域之 CORS 实战
众所周知,在javascript中使用ajax请求外部资源时有跨域限制。我们在讲解实战之前有必要搞清楚浏览器为什么要加这个限制,也就是要知其然也需要知其所以然。
不过,我们还应该先了解Cookie,在一个已经登录过的站点,浏览器会保存一个登录凭证,这个凭证就是保存在cookie中的其中一个值。有了登录凭证,在短时间内是不需要重新登录就可以访问该站点上属于用户的任何内容的。当我们登录了一个站点A,上面有一个按钮,其中显示“抽奖”,你也许会去点一下碰碰运气。但是这个抽奖按钮实际执行的动作也许你并不能从页面信息中准确无误的获取到,那如果这个按钮的背后行为是从你的银行账户转出一笔金额到一个盗窃者账户,现在你还敢点那个按钮吗?