Logstash 聚合插件 aggregate filter 的使用心得
在ELK常规的使用模式下,我们收集Nginx访问日志是按照单行进行的。这样比如说有10个用户请求,对应在ElasticSearch中就是10条记录(也称为10个document)。下面将分别描述此种收集方法的优缺点。
首先,这样的收集方式非常利于按照指定字段去搜索,并根据匹配的记录去查看其它字段的信息。比如统计客户端IP为 127.0.0.1 的请求有多少,使用IPhone 手机的请求有多少。当出现 499 、502 状态码时,看看这些请求的URL是什么,然后快速定位问题。这些方法都是非常非常实用而且好用的。
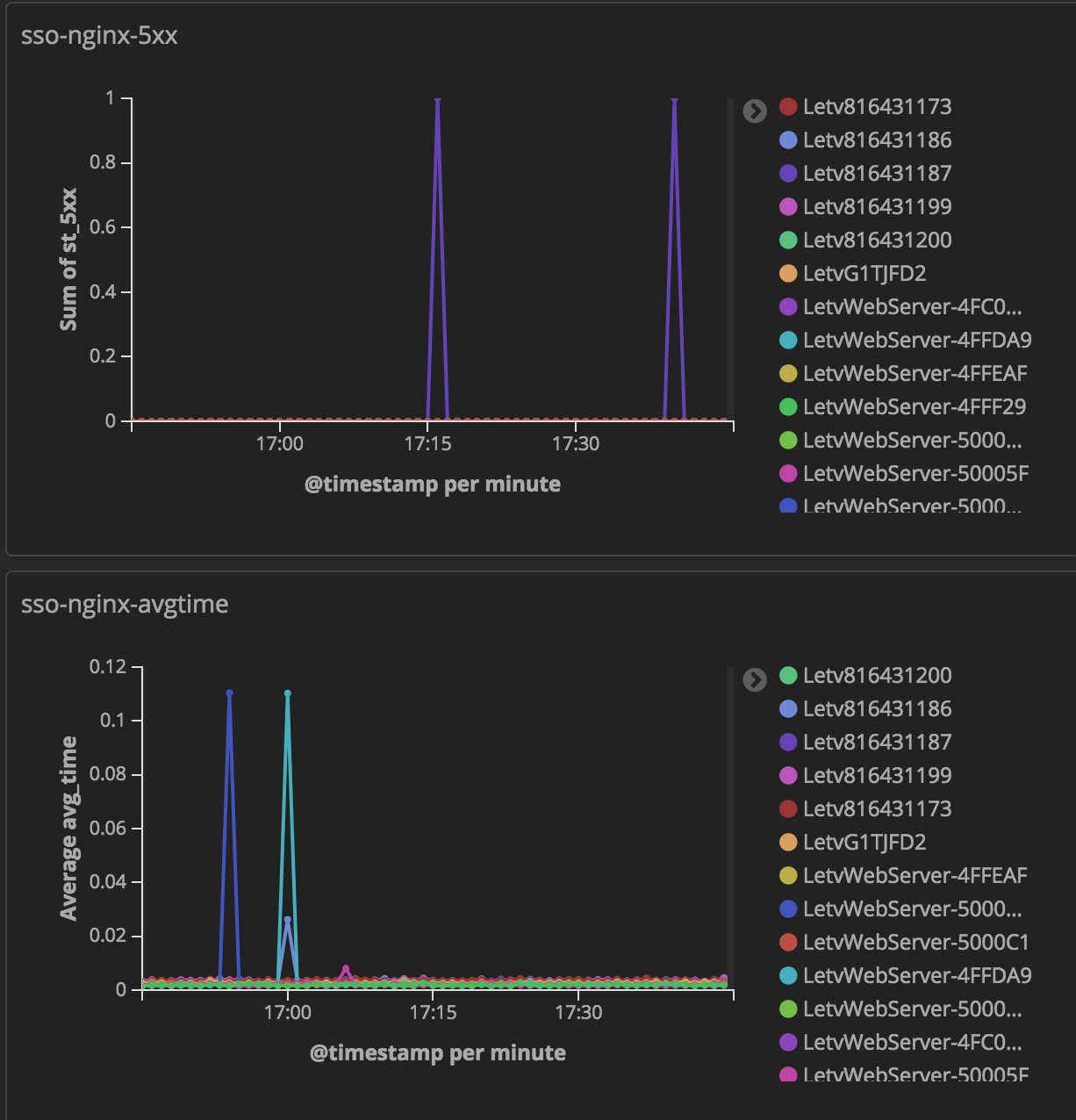
其次,除了上面的这些需求之外,我们还想要制作统计图,比如统计按时间范围统计总请求数,4xx 数量,5xx数量,响应时间超过 500ms的请求数,输出的字节数量,平均响应时间。特别是最后2项,时间范围跨度越长,数据量越大,计算时间就越长。据我们实际使用中的数据量,单个索引,每天 3亿的文档数量,对应就有120G左右的数据,在单个dashboard中同时展示上面的几种图标,如果时间跨度超过1小时,页面加载时间就会超过 2s 。而kibana又提供了自动刷新功能,这样如果有多个人同时使用 elasticsearch就会咔咔的慢。
另外,根据实际使用发现,elasticsearch的插入性能还是非常高的,其集群模式是具体可扩展性的。我们使用6台(24core 128G内存)的集群运行,现在平均 1w/s 的主分片索引速度(总分片是 2w/s),CPU使用率是 20% 左右。按照估算,最大索引速度应该可到 4w/s ,并且这都是默认配置,并没有经过参数调优。对于99%的业务,这个吞吐量级是一定能hold住的,所以可以不用担心索引速度了。不过在使用 ELK+Kafka的架构时,如果启用多个 logstash ,一定要为 kafka 的这些 topic 分派对应数量的 partition,不然可能不能最终到达 elasticsearch的数据量不高,并且还以为是 elasticsearch 的索引性能导致的。
当时,发现遇到搜索性能问题的时候,其实已经知道 logstash 提供日志聚合的插件,但是让我担心的时,我同时想要两种格式,第一种就是上面提到的,第二种就是把多条记录按一定的维度进行汇总后在插入到 elasticsearch,这样最后在 elasticsearch的文档(document)减少了之后,性能自然就提升了。一直以为,这两种格式,只能选其一,如果要同时支持就需要启动两套 logstash,并且使用不同的 cosumer-group 从kafka 消费2次数据。为了减少架构的复杂性,这个事情就一直搁置了。
在最近,实际使用 logstash 的聚合插件(aggregate filter)时,发现了我一直期待的结果,聚合的记录是以一个新的 event 输出的,并不影响原来每行一个的 event 。比如我要聚合 5 条数据,aggregate 会先把这5条数据输出,然后再输出一条聚合的数据。好,是我期望的功能,准备对原有的logstash filter 进行改造。
我们想要的统计图表都有这么些指标:总请求个数、慢请求个数、4xx个数、5xx个数、平均响应时间,字节数。维度有按域名、按服务器 分别展示上面的这些指标信息。

aggreate 插件大致有5种使用方式,我们这里是使用的第三种:Example #3 : no end event。有的场景是需要聚合的日志有开始、结束标记的,但是像nginx 日志,并没有很好的方式标记,其实针对我们的需求也不需要这样的标记。第三种方式就是设定一个 taskid ,使用 timeout 来控制一个聚合事件的结束。比如,我们的 taskid: %{request_host}_%{[beat][hostname]} 代表域名与主机名连接之后作为一个唯一标记,timeout: 20。这就意味着每20 秒,针对每个 taskid 创建一个聚合事件,如果 request_host / hostname 有 5 种组合,那么在 20 秒内就会创建 5 个聚合事件。为了可以按照不同的维度统计,因此 taskid 使用了这些维度相关的字段来保证每个聚合事件中聚合的这些记录都有相同的 request_host 与 hostname ,对应上面需求中的维度:域名、服务器。
aggregate 的第3种使用方式中还有2个配置,分别是 code 与 timeout_code , 这2个配置项的值是 支持ruby 语法的,并且可以使用 ruby 中的 if/elsif/end 以及常用对象方法,大大提高了配置的灵活性。另外,code 中可用字典类型的 map 变量,用于保存一些字段信息,当配置 push_map_as_event_on_timeout => true 时会自动把map变量的字段放入新的聚合事件中。code 中还可以使用 event.get(field) 与 event.set(field, value) ,在 code 中的 event 代指每次输入的单行事件,所以可以使用 event.get() 来获取字段信息,然后结合 ruby 代码来聚合数据之后,存入 map 变量中。timeout_code 中不可以使用上面的 map 变量,不过没关系,之前map中字段已经全部存放到聚合事件了,可以使用 event.get() 来获取之前在 map 中的字段,然后做最后的计算之后,再把新的计算结果通过 event.set 放入聚合事件中。重点需要区分的是 code 与 timeout_code 中的 event 指代的对象不是同一个。
其实经过一些ruby逻辑的处理,为了把一些变量传递到聚合事件中,我们可能把一些中间变量放入了 map 变量,但是最终不希望在 elasticsearch 中使用它,那在 aggregate 中是办不到的,只能通过 mutate filter 插件删掉。
到这里我就把 aggregate 配置贴出来,仅供参考。
# aggregate
# should be behind all custom filter
filter {
if "aggr-nginx" in [tags] {
aggregate {
task_id => "%{request_host}_%{[beat][hostname]}"
code => "
map['aggr'] ||= {};
map['request_host'] = event.get('request_host');
map['count'] ||= 0;
map['count'] += 1;
map['aggr']['total_time'] ||= 0;
map['aggr']['total_time'] += event.get('request_time');
map['bytes'] ||= 0;
map['bytes'] += event.get('bytes');
map['st_5xx'] ||= 0;
map['st_4xx'] ||= 0;
map['st_3xx'] ||= 0;
map['st_2xx'] ||= 0;
map['st_xxx'] ||= 0;
if event.get('status') >= 500
map['st_5xx'] += 1;
elsif event.get('status') >= 400
map['st_4xx'] += 1;
elsif event.get('status') >= 300
map['st_3xx'] += 1;
elsif event.get('status') >= 200
map['st_2xx'] += 1;
else
map['st_xxx'] += 1;
end
map['gt_500ms'] ||= 0;
if event.get('request_time') > 0.5
map['gt_500ms'] += 1;
end
map['gt_100ms'] ||= 0;
if event.get('request_time') > 0.1
map['gt_100ms'] += 1;
end
map['hostname'] = 'le.com';
if event.get('beat')
map['hostname'] = event.get('beat')['hostname'];
end
map['aggr']['index'] = event.get('@metadata')['index'];
"
push_map_as_event_on_timeout => true
#timeout_task_id_field => "task_id"
timeout => 20
timeout_code => "
avg_time = (event.get('[aggr][total_time]') / event.get('count')).round(3);
event.set('avg_time', avg_time);
meta_index = event.get('[aggr][index]').sub('access', 'count');
event.set('[@metadata][index]', meta_index);
"
}
}
}
另外,我们把普通事件与聚合事件分发到了 elasticsearch 的不同的索引(index)中,这样就可以非常方便的根据需要选择使用2种不同的索引(index)。其中上面针对 [@metadata][index] 的代码就是把原来索引名称中的 access 替换为 count,最后,普通事件的索引名称是 logstash-sso-nginx-access ,聚合事件的索引名称是 logstash-sso-nginx-count 。
最终到达 elasticsearch 中的结果分别是:
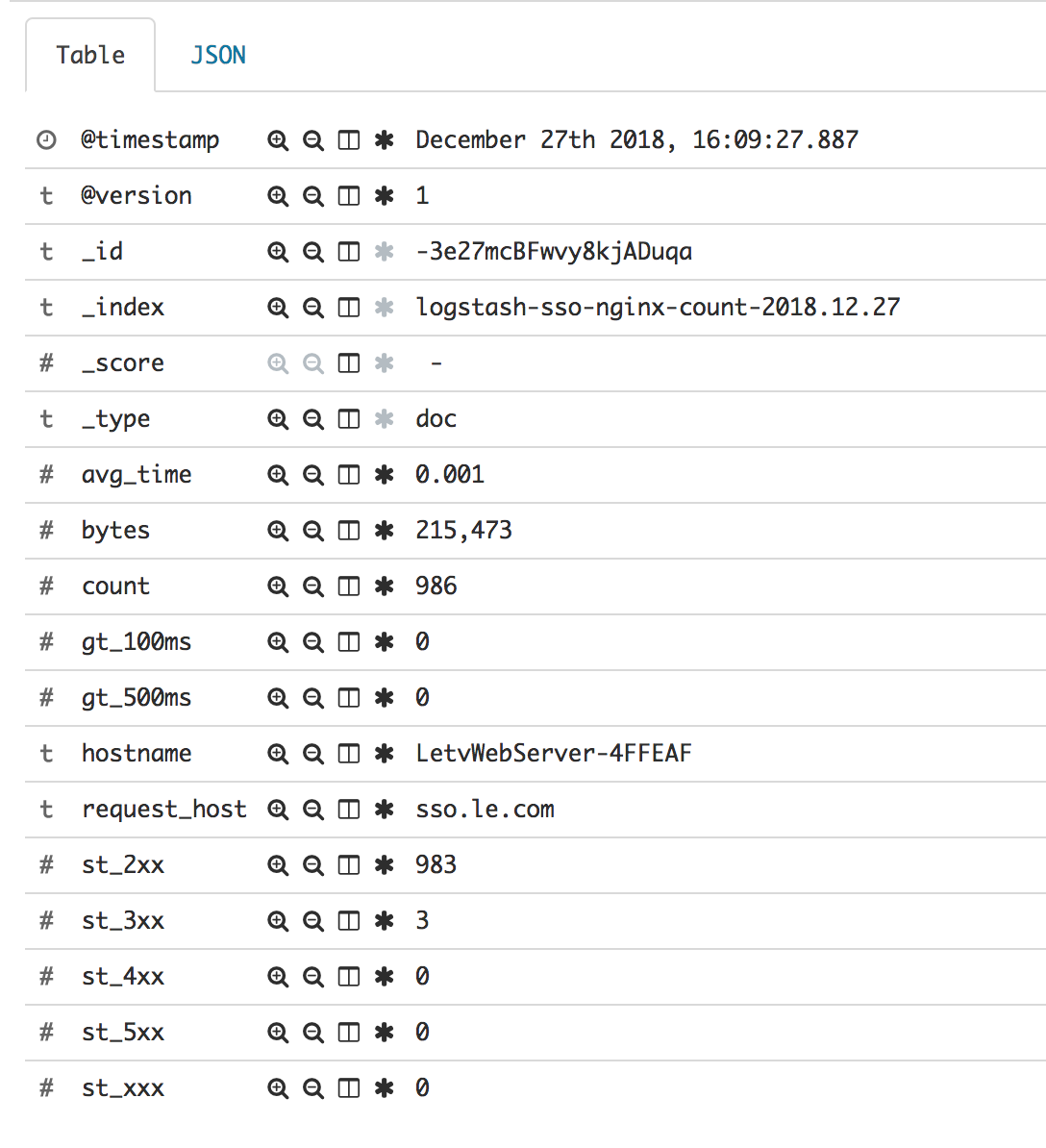
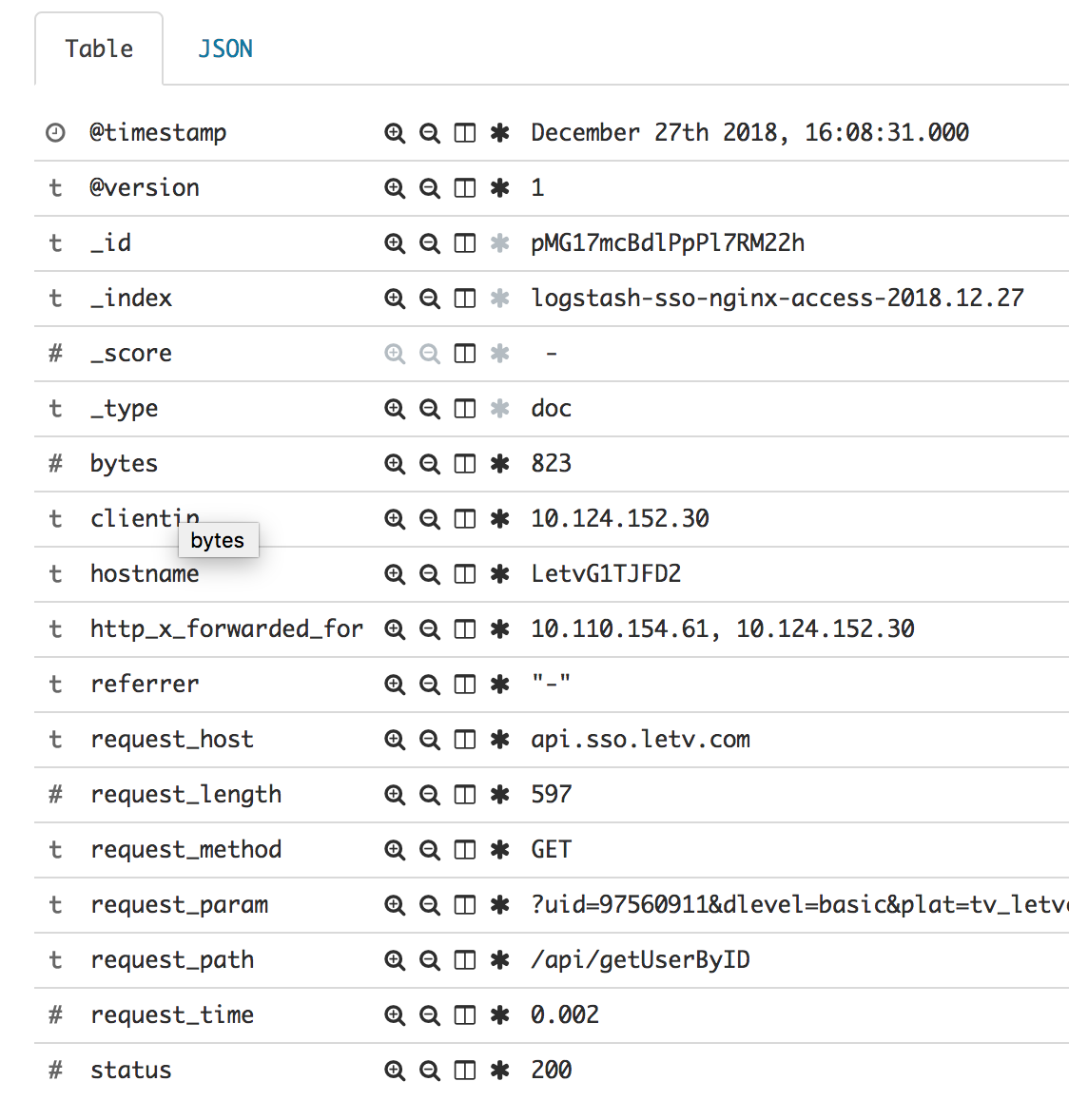
最后再提醒一下,aggregate 有几种使用方式,分别使用不同的配置字段,可以根据需要使用。event get/set 方法参数支持嵌套字段,可以参看上面示例,可以参考文章末尾的参考链接相关内容。
参考内容:
1. aggregate filter
2. logstash event api