MySQL InnoDB 之 Buffer Pool
Buffer Pool 是innodb 缓存表数据及索引数据的主要内存空间,允许频繁访问的数据直接通过内存访问。在专用的服务器上,通常把物理内存的80%以上分派给buffer pool。可想而知,Buffer Pool 也是利用内存缓存来提高性能的关键,因此如何合理利用 Buffer Pool 使其更好的体现价值是一个重要的话题。但为了适用各种各样的场景,Innodb 为这些可能的性能影响点都提供了配置项,允许根据具体场景设定对应的参数值以达到最佳的性能效果。
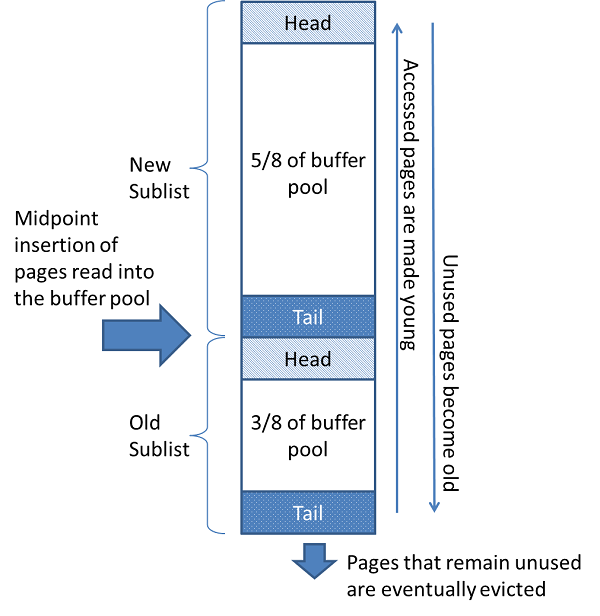
首先,我们来探讨一下 buffer pool LRU 算法,因为性能优化、参数调整都会涉及到这个关于 LRU 的话题。innodb 使用一个LRU的变种算法实现buffer pool 的管理。当需要增加一个新页到链表中时,最近最少使用的页被移除,新的页添加到列表的中间(midpoint)。这个中间点插入策略把这个链表按照2个子列表来对待:
a. 在头部,是最近被访问的页(young pages)的链表,称为:new sublistb. 在尾部,是最近很少被访问的页(old pages)的链表,称为:old sublist
这个算法,很大程度上保持页(pages)在 new sublist中。old sublist 中包含很少使用的页,这些页将随时可能被收回(evication)。
默认情况下,算法的实现如下:
a. buffer pool 的 3/8 用于 old sublistb. 链表的中点(midponit)是 new sublist 的 尾部(tail)与 old sublist 的头部(head)的分界线。
c. 访问在 oldlist 中的页使其变 “young”,将其移动到 new sublist 的头部(head)。如果一个页是由于用户的初始化操作被读入到 buffer pool中,那么第一次访问会立即发生,这个页会变“young”。如果一个页是由于预读(read-ahead)操作被读入到buffer pool 中,那么第一次访问并不会立即发生,也可以在这个页会回收之前都不会被访问。
d. 随着数据库的操作,buffer pool 中未被访问的页会逐渐老化,向链表的尾部(tail)移动。在 new sublist 或者是 old sublist 中的页会随着其他页更新而老化。在 old sublist 中的页(page)也会随着在 midpoint 中插入页而老化。最后,一直未使用的页将到达 old sublist 的尾部(tail),进而被回收。
默认情况下,查询读取到的页(page)会被立即移动到 new sublist 中,这意味着他们在buffer pool 中停留更长的时间。由mysqldump 操作、或者是一个没有where条件的查询语句执行造成全表扫描,可能会把大量的数据带入 buffer pool,同时回收相等数量的旧数据,即使新的数据不会被再次使用。类似地,由预读后台线程加载的页,与只访问一次的页(page)移动到 new sublist 的头部。这种情况将导致把频繁使用的页移动到 old sublist,最后将被回收。
1. 配置 InnoDB Buffer Pool 大小
关于 buffer pool 配置可以在启动时配置,也可以在运行时配置。相关的配置有这么几个:
innodb_buffer_pool_sizeinnodb_buffer_pool_chunk_size 块大小,默认128M。以1MB为单位增加或者缩小,只能在启动时配置。
innodb_buffer_pool_instances 实例个数
innodb_buffer_pool_instances 是根据配置设定,保持固定不变。但是针对 innodb_buffer_pool_size 与 innodb_buffer_pool_chunk_size 虽然提供配置项,但是会根据情况适当自动调整,最终寻找一个平衡点:innodb_buffer_pool_size = n * (innodb_buffer_pool_chunk_size * innodb_buffer_pool_instances),其中 n 是正整数。如果 n 小于 1 时,也就是说 innodb_buffer_pool_chunk_size * innodb_buffer_pool_instances 大于 innodb_buffer_pool_size 时,则会减小 innodb_buffer_pool_chunk_size 的大小,以使等式成立。当 n 小于 1 时,为什么不调整 innodb_buffer_pool_size 的值,而是调整 innodb_buffer_pool_chunk_size 的值呢???暂时还不知道确切的原因 ,有待进一步考究。
a. innodb_buffer_pool_size 的自动变化
比如:
innodb_buffer_pool_size = 9G innodb_buffer_pool_instances = 16 innodb_buffer_pool_chunk_size = 128M
innodb_buffer_pool_instances * innodb_buffer_pool_chunk_size = 16 * 128M = 2G,9 不能被 2 整除,因此 innodb_buffer_pool_instances 会自动上调到 10G,成为整数倍。所以,我们在设定 innodb_buffer_pool_instances 参数时最好是先计算一下,尽量保持设定的值与实际的值一致,做到符合预期,心里有数。
b. innodb_buffer_pool_chunk_size 的自动变化
比如:
innodb_buffer_pool_size = 2G innodb_buffer_pool_instances = 4 innodb_buffer_pool_chunk_size = 1G
innodb_buffer_pool_instances * innodb_buffer_pool_chunk_size = 4 * 1G = 4G,大于 innodb_buffer_pool_size 的大小,因此会缩小 innodb_buffer_pool_chunk_size 为 :2G / 4 = 512M
关于在线(OnLine)修改 Buffer Pool Szie 的知识点:
a. 在线配置 buffer pool size ,可以直接通过 SET GLOBAL 指令 完成。在 resizing 开始之前,所有通过 InnoDB API 执行的活动事务与操作需要先完成。一旦,resizing 操作开始进行,要求访问 buffer pool 的事务与操作必须等待直到resizing 完成为止。特殊是,当 buffer pool size 在调下(decreased),buffer pool 在碎片整理,对应页已被收回,这时 buffer pool 上的并发访问是允许的。b. 监控 Resize 进度。可以通过 SHOW STATUS 去查看,也可以在 server error log 中查看。
c. 内部实现又是如何呢?针对增加、减小的情况,分别来描述:
i: 增加。1> 在 chunk 中增加 page 。 2> 转换 hash table / list / 指针 使用新的内存地址。3> 增加 page 到 free list 中。总之,当执行增加操作时,其他访问 buffer pool 的线程都处于阻塞状态。
ii: 减少。1> buffer pool 碎片整理,收回空闲页(free page)。 2> 移除 chunk中的页(page) 3> 转换 hash table /list / 指针使用新的内存地址。总之,在执行减少操作时,只有第一阶段允许其他线程对 buffer pool 的并发访问。
2. 配置多个 buffer pool 实例
对于分配了大量尺寸的 buffer pool,把 buffer pool 划分到不同的实例,可以减少不同线程对缓存页的读写争夺,进而可以改善并发性能。多个实例配置,通过配置选项 innodb_buffer_pool_instances。在调整这个配置是,你可以需要适当调整 innodb_buffer_pool_size,原因见上文。
当 InnoDB buffer pool 很大时,许多数据的请求可以直接从内存中直接检索到。当多个线程同时访问 buffer pool 时,你可能会遇到瓶颈。这时,可以开启多个 buffer pool 以减少这种争夺。在 buffer pool 中每个页(page)的读写会使用 hash 函数使其随机的分派到其中一个 buffer pool。每个buffer pool 管理其自己的 free list/ flush list /LRUs / 以及其他连接到 buffer pool 的数据结构,并使用自己的互斥锁(mutex)进行保护。
为了开启多个buffer pool 实例,需要设置 innodb_buffer_pool_instances 大于1、小于等于 64 ,默认值为 1,最大值为 64。并且,只有当 innodb_buffer_pool_size 配置为大于等于1G时,这个功能才会生效。你指定的 innodb_buffer_pool_size 的总大小会被分到所有的 buffer pool 实例中。因此,为了最好的效率,innodb_buffer_pool_size 与 innodb_buffer_pool_instances 一起设置,以使得每个 buffer pool 的大小至少为 1G。
3. 配置针对 buffer pool 扫描的限制
Innodb 使用了一项技术,减少了不会再次被访问数据载入 buffer pool 的数据量。这样做的目标是确保频繁访问的页(hot pages)保留在buffer pool 中,正如预读(read-ahead)以及全表扫描(full-table scans)加载了新的数据块,这些块以后可能会访问,也可能不会被访问。
最近访问的块被插入到 LRU list 的中间。最近访问的页,默认会插入到距 LRU list 末尾 3/8 处。每当页(page)在buffer pool 中第一次访问时,这些页会被移动到链表的前面。因此,不会再次访问的页绝对不会移动到LRU list 的前面区域,结合 LRU 策略,这些页不久将会老化。这样的布局把 LRU list 划分成了2 部分,在插入点(inseretion point)下游的页被认为是老化的,认为可以被LRU策略回收。
你可以控制LRU list 中的插入点(insertion point),选择是否优化由于表扫描、索引扫描导致数据载入到buffer pool 中的问题。innodb_old_blocks _pct 控制了 old sublist 在整个 LRU list 中的占比,默认是 37,也就是3/8。取值范围为 5(在buffer pool 中的新页将很快被淘汰) 到 95 (意味,只为 hot 页保留了5%的空间,这将使得算法更加接近与熟悉的LRU策略)。
这项优化同样可以避免由预读(read ahead)导致 innodb 对 buffer pool 资源的低效处理。在这些扫描中(scan), 一个数据页典型的是在短时间访问了几次,之后不会被再次访问。配置参数 innodb_old_blocks_time 指定了一个在第一次访问到实际移动这个数据页到new sublist 头部的时间窗口,单位为:毫秒。默认 值为 1000 ,即为 1000 毫秒。增加这个值,将使得越来越多的块可能更快的从 buffer pool 老化,进而被回收。
innodb_old_blocks_pct 与 innodb_old_blocks_time 可以在配置文件中指定,也可以在运行时通过 SET GLOBAL 语句设置。
为了帮助我们估计设置这些参数的影响,SHOW ENGINE INNODB STATUS 命令汇报了 buffer pool 的统计信息。具体请参考官方文档。
因为这些参数的影响会由于你的硬件、数据、工作负载而变化较大,所以在性能关键点或者是生产环境修改这些值时进行基准测试验证实际效果。
在混合工作负载的情况下(多数活动是 OLTP,伴随着定期批量统计查询导致较大的扫描),在匹配执行时设定 innodb_old_blocks_time 可以有效的帮助正常负载的数据集保持在 buffer pool 中。
当扫描一些大表,其数据不能完全放在 buffer pool 中时,设置 innodb_old_blocks_pct 为一个比较小的值,使其只访问一次的数据不会占用 buffer pool 中太多的空间。比如,设置 innodb_old_blocks_pct = 5 ,限制了只访问一次的数据只占用 buffer pool 中 5%的空间。
当扫描一些小表,其数据可以完全放入 buffer pool 中时,在 buffer pool 中移动页(pages)只有很小的开销,因此你可以保持 innodb_old_blocks_pct 为默认值,或者更高,比如 innodb_old_blocks_pct = 50。
关于 innodb_old_blocks_time 参数的效果比 innodb_old_blocks_pct 更难预测,相对较小,但是随着工作负载变化较大。为了能够达到一个最佳的效果,如果通过调整 innodb_old_blocks_pct 并不明显的话,进行基础测试吧。
4. 配置 Buffer pool 的预取机制(pre-feching/ read-ahead)
read-ahead 请求是在 buffer pool 中异步的预取多个页的I/O请求,在预期中,这些页将很快被使用。预取请求把在 extent 中的所有页都加载到buffer pool 中。innodb 使用2种 read-ahead 算法来改善I/O性能。
什么是 extent 呢?
extent 是指在tablespace 中的一组页(pages)。根据页大小的不同而不同,对于页大小(pages size)为 4KB/ 8KB/ 16KB 时,extent的大小为 1MB。在Mysql 5.7 中,增加了对 32KB /64KB 页大小的支持,此时,32KB的页对应的 extent 为 2MB,而对于 64KB的页对应的 extent 为 4MB。Innodb 的一些特征,如 segments /read-ahead 请求/ doublewrite buffer 使用到的 I/O请求(read / write / allocate / free data),每次操作一个 extent ,而不是一个页(page)。
线性 read-ahead 是基于 buffer pool 中页总是被连续访问的模型来预测哪些页可能很快被使用到。可以通过调整连续访问的页的数量来控何时执行 read-ahead 操作,对应的配置参数为 innodb_read_ahead_threshold。在这个参数增加到 innodb 之前, innodb 只会当读取当前 extent 的最后一页时才启动一个异步预取请求,预取下一个 extent 的全部页。
配置参数 innodb_read_ahead_threshold 控制了 innodb 在顺序页访问模式的敏感度。如果在一个 extent 中顺序访问的页数量大于等于 innodb_read_ahead_threshold 时,innodb 开启一个针对extent 中后续的所有页( the entire following extent)的异步预取操作。innodb_read_ahead_threshold 的取值范围为 0-64,默认值为56。越高的值表示更严格的访问模式检查。此项配置可以在配置文件中设置,也可以在运行时动态设置。
随机 read-ahead 也是基于 buffer pool 中页来预测哪些页可能很开被使用到,但是它不管这些页读取的顺序。如果在buffer pool 中找到在一个 extent 中连续的 13个页,则异步预取这个extent 中其他的所有页。这个机制通过 innodb_random_read_ahead = ON 来开启。
命令 SHOW ENGIN INNODB STATUS 可以显示一些统计信息,可以帮助评估 read-ahead 算法的效果。其中包括的统计信息包括(innodb_buffer_pool_read_ahead / innodb_buffer_pool_read_ahead_evicted / innodb_buffer_pool_read_ahead_rnd)。在调整 innodb_random_read_ahead 时,这些信息可能是有用的。
5. 配置 buffer pool 的冲刷(flushing)
Innodb 会在后台(background)执行某些任务,包括冲刷 buffer pool 的脏页(dirty pages)。脏页(Dirty pages)指页数据已经被修改,但是未被写入磁盘数据文件中。
在Innodb 5.7中,buffer pool 冲刷是由页清理线程(page cleaner threads)来执行的。页清理线程数可以提供 innodb_page_cleaners 变量进行配置,默认值是 4 。
Buffer pool 的 flushing 在脏页到达低水位(low water mark)时开始,这个值可以通过变量 innodb_max_dirty_pages_pct_lwm 变量调整。默认值为 0,即关闭较早的 flushing 行为。
innodb_max_dirty_pages_pct_lwm 阀值的目的是控制 buffer pool 中脏页的比例,防止到达脏页的最大阀值 innodb_max_dirty_pages_pct ,默认值时 75 。如果脏页触达 innodb_max_dirth_pages_pct 定义的最大阀值时,innodb 将会侵略性的开始 flush 脏页。
有一些额外的变量允许调整 buffer pool 的 flushing 行为:
a. innodb_flush_neighbors
innodb_flush_neighbors 定义是否同时 flush 同一个 extent 中的其他脏页。有 3个值可以设置。1> 设置为 0 表示关闭这个功能,也就是在同一个 extent 中的脏页不会被 flush。2> 设置为 1 表示 flush 在同一个 extent 中邻近的脏页。3> 设置为 2 表示 flush 在同一个 extent 中的所有脏页。
当数据存储在传统的 HDD 存储设备上时,与flush N 个页使用 N 次 IO 相比,一次操作 flush 相邻的页可以减少 I/O 开销。对于存储在 SSD 上表数据,你可以关闭这项设置把写操作分开。
b. innodb_lru_scan_depth
innodb_lru_scan_depth 指定了针对每个 buffer pool 实例,在 buffer pool LRU list 下,页清理线程(page cleaner thread)扫描以寻找需要 flush 的脏页的程度。这是一个由也清理线程每秒执行一次的后台操作。
一个小于默认值的配置,在多数工作负载情况下通常是合适的。一个明显高于需要的值坑呢影响性能。只有当你有额外的 I/O 能力,再考虑增加这个值。相反,如果一个写集中的工作负载使其I/O接近饱和,则减少这个值,特别是在一个较大的 buffer pool 实例中。
当调整 innodb_lru_scan_depth 时,起初设置一个较小值,再根据情况向上调整,目标是很少看到无空闲页面。另外,当改变 buffer pool 实例数量时,也考虑调整 innodb_lru_scan_depth ,因为 innodb_lru_scan_depth * innodb_buffer_pool_instances 定义了页清理线程执行的工作数量。
innodb_flush_neighbors 与 innodb_lru_scan_depth 这2项配置主要是为了用于写密集型工作负载。如果有大量的 DML 活动,如果不进行侵略性的 flush ,flush 可能会落后。如果 flush 太频繁又会导致 I/O 容量饱和。理想的设置取决于你的工作负载、数据访问模式、存储配置(如,是否数据存储在HDD 还是 SSD 设备上)。
自适应的 Flushing (Adaptive Flushing)
Innodb 使用一种基于 redo log 生成速度与 flushing 当前状态的算法来动态调节 flushing 速度。这个目的就是通过让 flush 活动与当前负载保持一致,进而平滑总体的性能。自动调节 flush 速度可以避免因突发的IO活动导致吞吐量的突然下降,这可能是由于在正常的读写活动上 flushing 造成的。
在写密集型的工作负载,生成了很多的 redo entries ,这将可能使吞吐量突然改变。例如,当innodb 想重新使用 log 文件中的一个区域(portion),这时可能产生一个尖峰。在重新使用前,所有在那个区域(portion)的 redo entries 必须要先flush到磁盘中。如果log 文件变满,也将导致一个吞吐量临时下降。即使未达到 innodb_max_dirth_pages_pct 阀值,这种情形也是会发生的。
adaptive flushing 算法通过追踪 buffer pool 中的脏页数量与 redo log 记录生成的速度,帮助避免了这些情形。基于这些信息,它决定每秒从buffer pool 中 flush 有多少脏页,允许管理负载的突然变化。
innodb_adaptive_flushing_lwm 变量为 redo log 容量定义了一个低水位(low water mark)。当阀值到达时,即使 innodb_adaptive_flushing 变量是关闭的,但是 adaptive flushing 仍将被开启。
内部基础测试结果表明,这种算法不仅可以在一定时间内保持吞吐量,而且可以显著的提高整体的吞吐量。然而,adaptive flushing 可能明显影响某些工作负载的IO模式,可能并不适合所有的场景。当 redo log 有填满的风险时,它提供了最大的好处。如果 adaptive flushing 并不适合你的工作负载特征,你可以关闭。Adaptive flushing 使用 innodb_adaptive_flushing 变量控制,默认是开启的。
innodb_flushing_avg_loops 定义了保持与之前 flushing 状态相同的迭代次数,控制着 adaptive flushing 与前台工作负载变化的反应速度。一个较高的 innodb_flusing_avg_loops 意味着保持之前计算的快照更久,因此 adaptive flushing 反应速度会变慢。当设定一个较高的值时,确保 redo log 的使用率不会超过 75% (硬编码限制,异步的flushing 启动),并且innodb_max_dirty_pages_pct 阀值与当前工作负载保持在一个水平。
对于稳定工作负载的系统,有一个较大的尺寸的日志文件(innodb_log_file_size)与很小的峰值(日志文件使用率未达到 75%)时应该使用一个较大的 innodb_flushign_avg_loops 值,以使 flushing 保持尽可能的平稳。对于具有极端的负载峰值(extreme load spikes)或者是没有太多的空间的系统,那么一个较小的值允许 flushing 密切跟踪工作负载,帮助避免到达 75%的日志空间使用率。
注意,如果 flushing 落后时,buffer pool flushing 的速率可能超过 InnoDB可用的 IO 容量,这个是通过 innodb_io_capacity 设置。但是在这种情形下, innodb_io_capacity_max 定义了一个最大的 IO 容量的限制,以使 IO 活动的峰值不会耗尽服务器的所有IO容量。
innodb_io_capacity 设置是针对所有的 buffer pool 实例的。当脏页需要被 flush 时,IO 容量被平均到 buffer pool 的实例(buffer pool instances)中。
6. 保存、恢复 Buffer Pool 状态
为了减少在重启服务后的变暖(warmup)周期,InnoDB 为每个 buffer pool 在服务关闭时保存了一定比例最近使用的页,在服务再次启动时恢复这些页。用于存储最近使用页的百分比是由 innodb_buffer_pool_dump_pct 来配置。
在重启一个繁忙的服务后,有一个稳定增加吞吐量的变暖(warmup)周期,因为在buffer pool 中的页需要重新写会到内存。恢复 buffer pool 的这种能力,通过重新直接从磁盘上加载之前在 buffer pool 中的页,而不是等 DML 操作访问对应的行,使得缩短了变暖(warmup)的周期。而且, IO请求也可以大批量执行,使得整体的 IO 操作更快。页加载(page loading)是在后台运行,并不会延迟数据库的启动。
此外,除了在关闭时保存 buffer pool 状态以及启动时恢复 buffer pool,你可以在服务运行时的任何时间保存及恢复 buffer pool 状态。例如,你可以在稳定负载下到达了稳定的吞吐量时保存 buffer pool 的状态。你也可以在运行了报告及维护的任务之后,恢复到之前的 buffer pool 状态,这些任务把一些只有这些操作需要的数据带到了 buffer pool,或者是允许了一些其他非常规的工作负载。
即使,buffer pool 可能占有好几个G,但是 Innodb 把 buffer pool 中的数据保存到磁盘时是很小的 。只有 tablespace IDs 以及查找合适的页所需要的 page IDs 会保存到磁盘中。这些信息来源于 INNODB_BUFFER_PAGE_LRU.INFORMATION_SCHEMA 的表中。默认,tablespace ID 与 page ID 数据保存名为 ib_buffer_pool 的文件中。文件名及位置可以使用 innodb_buffer_pool_filename 配置项修改。
因此数据会随着普通的数据库操作而在 buffer pool 中进行缓存(cache),或者老化(age out),所以如果磁盘上的页(disk pages)最近被更新了,或者是一个 DML 操作中包含的数据没有被加载进buffer pool 中,这都不是问题。加载机制将会忽略已经不存在的页。
底层原理包含了一个异步线程,会分派执行 dump 与 load 操作。
压缩表的磁盘页(disk pages)将会已他们的压缩格式加载到 buffer pool 中。当DML操作访问到这些页的内容时,这些页将按正常解压缩(uncompressed)。因为解压缩页是一个CPU密集型的操作,因此在一个连接线程中并发执行比在执行 buffer pool 恢复操作的单个线程中更高效。
可以通过 innodb_buffer_pool_dump_pct 来设置导出 buffer pool 的百分比,可以在配置文件中设定,也可以在运行时设定。可以通过 innodb_buffer_pool_dump_at_shutdown 与 innodb_buffer_pool_load_at_startup 来设定关机自动保存及开启自动加载,默认值,应该是启用状态。
在 Mysql 5.7 中当 innodb_buffer_pool_dump_at_shutdown 与 innodb_buffer_pool_load_at_startup 开启时,innodb_buffer_pool_dump_pct 的默认值会从 100 变为 25%(只导出25%最近最常访问的页)。
也可以通过 SET GLOBAL innodb_buffer_pool_dump_now=ON / SET GLOBAL innodb_buffer_pool_load_now=ON 来开启一次导出或者导入,同时可以 SHOW STATUS LIEK 'Innodb_buffer_pool_dump_status' 来查看执行进度。
另外,我们也可以通过 Performance Schema 来监控 Buffer Pool 加载进度。