Base64 编码
Base64,是一种二进制数据转换为可打印字符的编码。用于一些不支持二进制数据的场景。比如常见的 HTTP 、SMTP 协议是文本协议,其中要传递一些二进制的数据(如:AES算法加密后的数据)时就需要把其转换为文本形式的字符串。Base64编码后的数据有2个特性,其一是文本字符串,其二是这些字符还是可打印的。
二进制转换为普通文本的编码,英文称为:Binary-to-text encoding。也是有很多种形式,除了Base64,还有 BinHex,就是把二进制数据转换为16进制字符串的形式。
目前已知的第一次标准化使用是在1987年的RFC989中提出的 PEM (Privacy-enhanced Electronic Mail) 协议中。其中使用到的加密算法输出的是二进制数据,而其协议只支持ASCII,因此使用Base64编码来将其二进制数据转换为文本格式。当前的PEM版本是在RFC1421中制定的。多目的的因特网邮件扩展(MIME:Multipurpose Internet Mail Extenstioins)的Base64编码是基于PEM的RFC1421版本,制定在RFC2045中。这2种Base64编码使用相同的64个字符,以及使用等号(=)来填充。后来,在RFC4648(旧版本为RFC3548)中专门为Base系列(Base16/Base32/Base64)制定了规范,这个规范除了MIME 中提到的Base64编码格式,还提到了另外一种为URL与文件名提供的Base64编码格式。
常常说的Base64,即MIME形式的Base64 编码,使用64个字符来表示6个二进制位组成的每个值,也就是说3个字节长度的数据需要使用4个Base64字符表示。这64个字符,其中 A-Z / a-z / 0-9 表示前62个字符,剩下两个字符分别用 + / 表示。在一些场景下,最后2个字符会使用其他字符来替代。比如,RFC4648中提到的为URL与文件名提供的Base64编码格式,由于文件名与URL地址中/ 表示目录分割符,以及在URL中空格会被编码为加号(+),因此最后2个字符分别使用 减号(-)与 下划线(_)。在RFC4648中把这种称为 “base64url” ,要注意与Base64是不是完全相同的。
以上说的这2种Base64的编码形式是web开发中比较常见的,另外还有一些其他场景下的Base64会把最后2个字符替换为其他的符号,一定要明白这么做,是为了规避具体场景下的一些问题。
那么,还有一些使用64个字符来编码二进制数据的编码,这些成为 Radix-64,有的可能是与MIME Base64的64个符号完全不同,有的可能是序号不用,这种可以成为与MIME Base64 不兼容。比如,Unix 系统中的 /etc/shadow 用来保存用户密码的hash值,使用的就是Radix-64形式的编码,称为B64。使用的64个字符是:./0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz ,并且没有使用填充(Padding)。
了解了这些背景知识之后,接着就详细展开MIME Base64的编码实现细节了。Base64中的64个字符都有一个编号(编号范围为 0 - 63)。如下图所示:
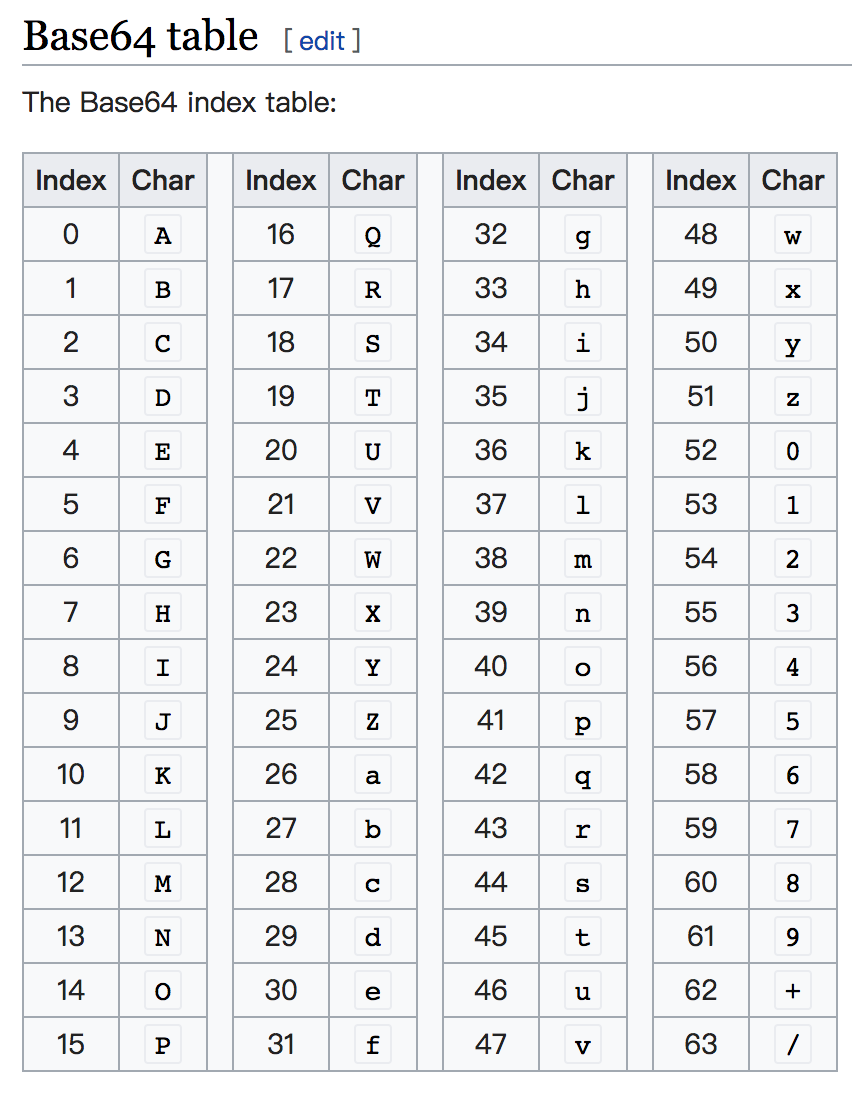
二进制到Base64编码的过程是把二进制的每6位使用一个字符表示,也就是计算这6个二进制位的值,转化为十进制值,然后根据编号找到对应字符,依此类推,对每6个二进制位执行这个操作,然后把这些字符连接起来形成一个字符串。Base64字符串解码为二进制数据的过程是把每个字符转换为编号,然后把这个编号转为二进制值,依此类推,对每个字符执行这个操作,然后把这些二进制位连接起来形成一个完整的二进制数据。
Base64 编码(下面的各个位之间的空格没有特殊的含义,只是为了显示上的更加直观)。
// 二进制格式: 000000 000001 000010 000011 100000 // 每6个位对应的十进制值: 0 1 2 3 32 // base64 格式: A B C g
如果我们对一个字符串进行Base64编码,那也是相同的原理。先根据不同的字符编码计算出对应字符串的二进制表示形式。比如,在UTF8编码中,26个英文字母依然使用 ASCII 码表示,占用一个字节;而常用汉字则占用3个字节。
在计算机内部常常使用字节为最小单位来储存数据(如字符串、图片等等),1个字节占用8个二进制位。那么,比如有一个ASCII字符串的长度是 20,也就是需要使用 20x8=160个二进制位表示,160并不能被6整除(余4),那么最后的4个二进制位怎么办?最后如果不够6位,则把不足的位用0表示,然后再计算其值,最后根据这个值再转换为Base64字符。
// 二进制格式: 000000 000001 000010 0001 // 二进制格式(补位后): 000000 000001 000010 000100 // 每6个位对应的十进制值: 0 1 2 4 // base64 格式: A B C E
前面提到,每3个字节的数据需要4个Base64字符表示,为了保证Base64编码后的字符长度符合这个规律,那么就出现了填充机制,填充字符为等号(=)。如果最后正好剩3个字节,那么将被编码为4个字符,不进行填充;如果剩1个字节,那么这8位二进制序列会被编码为2个字符,最后填充2个等号(=);如果剩余2个字节,那么这16位二进制序列会被编码为3个字符,最后填充1个等号(=)。
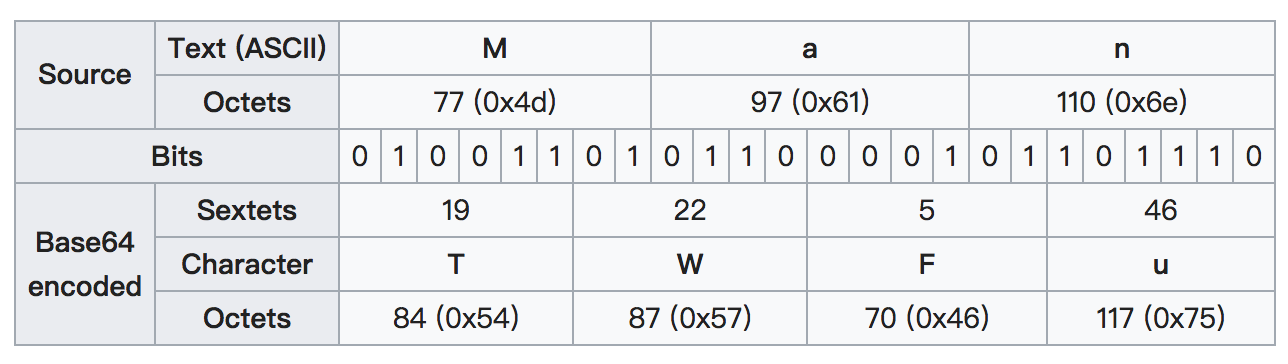
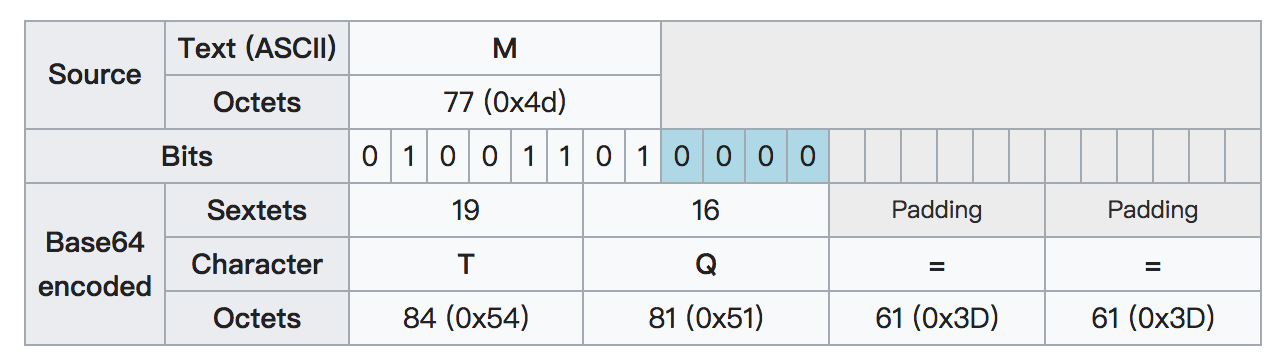
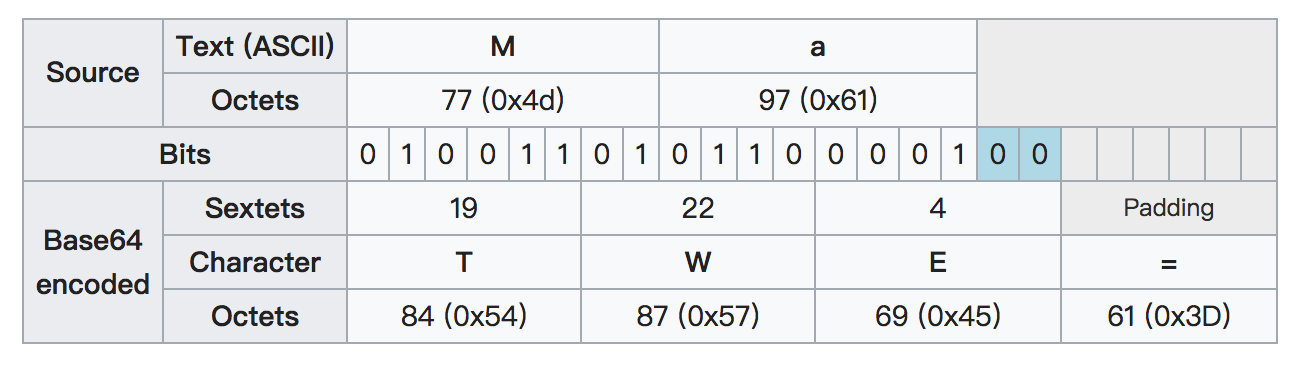
返回来,也可以理解为:当Base64编码后字符串末尾有两个等号(==)表示原数据的最后一组包含1个字节;当末尾有一个等号(=)表示原数据的最后一组包含2个字节。如图:
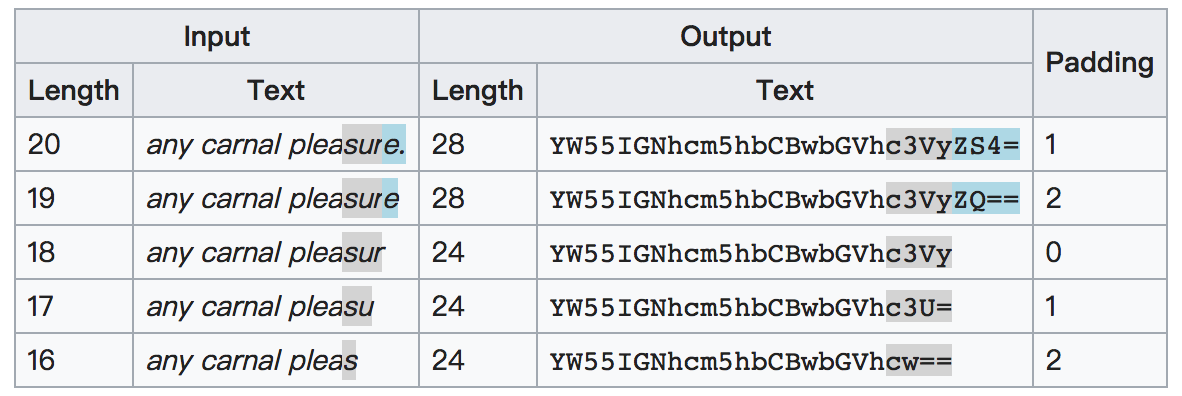
相同的ASCII字符编码为Base64字符后,由于位置的不同也会对应为不同的字符,这也正是由于每3个字节转换为4个Base64字符时的错位而产生的结果。如图:
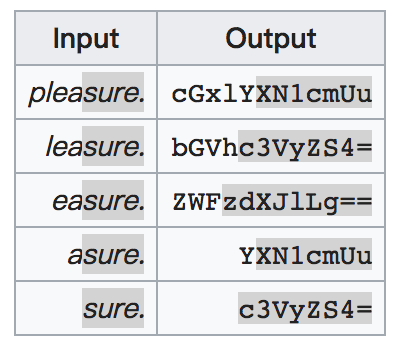
Base64编码后的字符长度比原来的字节数要长,比例是 4:3。如果在UTF8编码下(一个ASCII字符占用一个字节,即字符数等于字节数),对ASCII字符串进行Base64编码,编码后字串比原始字符串要长33.33% 。
有时,可能会不使用填充模式,比如在URL中为了避免等号(=)识别为赋值符号。其实根据 3:4的计算方式,可以直接计算出末尾省去的等号个数。Base64解码并不依靠最后的填充字符(=),但是一些编程语言实现的解码函数则要求被解码的字符串必须是完整的Base64格式,不能省去最后填充的字符(=)。
这里提供一个PHP版本的base64url的实现,如下:
<?php
function base64url_encode($data) {
return rtrim(strtr(base64_encode($data), '+/', '-_'), '=');
}
function base64url_decode($data) {
return base64_decode(str_pad(strtr($data, '-_', '+/'), strlen($data) % 4, '=', STR_PAD_RIGHT));
}
?>
参考:
Base64
Binary to text encoding