Redis Replication 实现原理
对于 Master/Slave 模式,在我们常用的Mysql中你一定有或多或少的了解,应该知道它的一些价值,比如灾备、读写分离。就灾备一项就足以使我们必须使用它,因为一旦服务器软硬件故障,可能造成数据永不可恢复。你可能会说,可以提前做好数据文件备份,但是要远比修改一个 IP 更加复杂与时间开销更大。在Master/Slave 模式下还可以结合LVS/Keepalived 实现故障自动转移,使其具体业务方无感知。
在 Redis 2.8 版本之前,Master/Slave 之前只支持全量同步(full resync),从 2.8版本开始支持了部分重同步(partial resynchronization),使得在短暂的网络中断恢复后,不需要进行全量数据同步,而是只同步最近新增的数据即可。那么如何理解这个“短暂”,其实是取决于配置参数与实际场景,下面将带大家一起抽丝剥茧,找出真相。
要配置 Master/Slave,我们只需要在对应Slave节点上执行命令 SLAVEOF masterip masterport , 如果之前有配置其他的Master,此命令也会继续执行。如果要取消 Master/Slave 关系,可以在对应Slave节点上执行 SLAVEOF NO ONE 。但是对于 SLAVEOF masterip masterport 命令的返回结果只是代表成功记录了Master信息,在返回结果前并不实际去与Master建立连接。
我们可以通过 INFO replication 查看Master/Slave 的实际同步状态。执行相同的命令,在Master与Slave节点上输出的信息是不同的,这是为了支持Slave节点(Slave')下继续配置 Slave节点(Slave'')(在此种状态下,对于 Slave'' 来说,Slave' 是其Master,因此对于 Slave' 在不同的视角有两种角色),所以在Slave节点下看到的条目是比较多的。但并不是说明我们只看 Slave节点的输出就可以的,这样的话就大错特错了。不管整个复制是有几级,INFO replication 命令显示的信息也是与之直接连接的节点相关。
视角(view point),这个词我感觉需要先理解下。因为就同一节点,可能对于其他不同的节点来说其扮演的角色是不同的(如上所述),这样我们把他描述为 Master 节点还是 Slave 节点呢?不论哪一种都会产生二义性,因此为了避免这种情况,我们将会不吝啬的使用“视角”这个词。
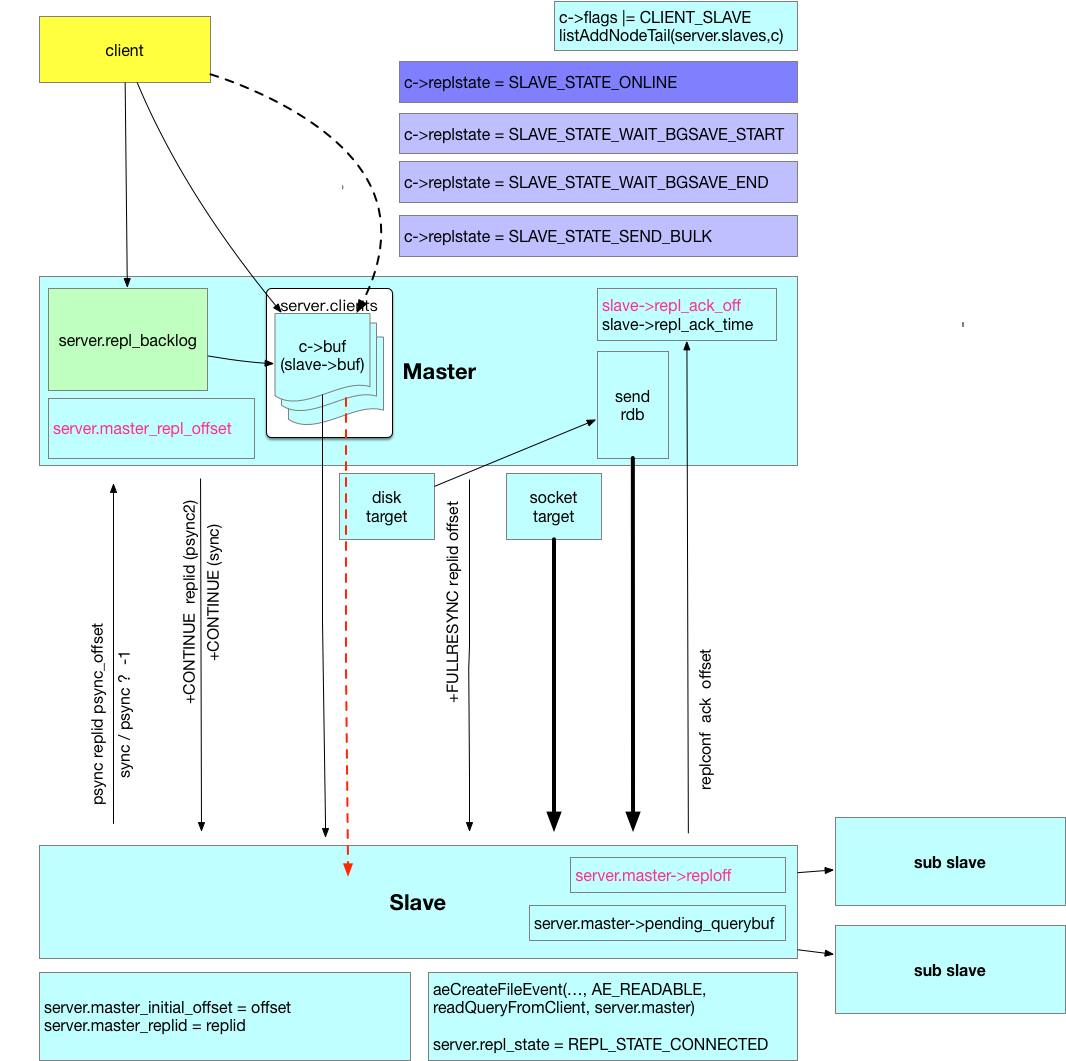
在详细阐述实现细节前,我们在脑海中应该对整个架构有个大概的轮廓,先大致理解下:
在master 节点上对客户端的“写命令”的字符长度的累加值称为 offset。有新的写命令,offset 则增加相应的数值。整个复制过程都是围绕着这个 offset 进行的。比如,新配置了一组 master/slave ,那么 slave 首先会复制 master 现有的数据,然后再接收master 转发过来的客户端命令执行相应的处理,最终达到数据同步的目的。在复制 master 现有数据的过程中,为了保持 master 继续可用,那么就要记录在复制过程中新接收的客户端命令,这些命令将保存在 backlog 中。通过什么机制来了解现在master/slave间的数据是否有差异呢?那就是 offset,如果master 上的最新的 offset 与 slave 上的相同,那么代表 master/slave 数据一致。当然,在整个复制过程中,为了解决其他问题,会保存不同用途的 offset 字段。Master 视角下将会有这些信息:
127.0.0.1:6001> info replication # Replication role:master connected_slaves:1 slave0:ip=127.0.0.1,port=6002,state=online,offset=76650,lag=0 master_replid:8ce61acd3456a26ff2030f147784936ad116219a master_replid2:0000000000000000000000000000000000000000 master_repl_offset:76650 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:76650Slave 视角下将会有这些信息:
127.0.0.1:6002> info replication # Replication role:slave master_host:127.0.0.1 master_port:6001 master_link_status:up master_last_io_seconds_ago:8 master_sync_in_progress:0 slave_repl_offset:76790 slave_priority:100 slave_read_only:1 connected_slaves:1 slave0:ip=127.0.0.1,port=6003,state=online,offset=76790,lag=1 master_replid:8ce61acd3456a26ff2030f147784936ad116219a master_replid2:0000000000000000000000000000000000000000 master_repl_offset:76790 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:76790Subslave 视角下将会有这些信息
127.0.0.1:6003> info replication # Replication role:slave master_host:127.0.0.1 master_port:6002 master_link_status:up master_last_io_seconds_ago:3 master_sync_in_progress:0 slave_repl_offset:76916 slave_priority:100 slave_read_only:1 connected_slaves:0 master_replid:8ce61acd3456a26ff2030f147784936ad116219a master_replid2:0000000000000000000000000000000000000000 master_repl_offset:76916 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:71 repl_backlog_histlen:76846slave 节点还有这两种状态,分别再次会追加一些信息:
server.repl_state == REPL_STATE_TRANSFER master_sync_left_bytes:1 master_sync_last_io_seconds_ago:2
server.repl_state != REPL_STATE_CONNECTED master_link_down_since_seconds:3
每一项的解释如下:
role: 当前节点的角色,在层级复制中,只有顶层的节点才会显示为 master,其他都为 slave
connected_slaves: 与当前节点成功连接的slave节点个数。
slave[n]: 与当前节点成功连接的slave节点列表。其中 ip/port 为 slave 节点对应的 ip/port 信息,state 为在当前节点视角下这个slave 所处的状态,offset 为复制偏移量,lag 为延迟时间(最近一次回复到现在的时间差,单位为:秒)。state字段可能的值有3个: wait_bgsave 、 send_bulk、online。这里的 offset 与 lag 是对应的,是 slave 通过命令 REPLCONF ACK offset 来通知master 其最新的 offset,然后 master 节点把这个 offset 登记为 repl_ack_off,接收时间登记为 repl_ack_time,上面显示的 offset 就是 repl_ack_off 的值 ,lag 显示的是当前时间戳减去 repl_ack_time 的秒数。
master_repl_offset: master 节点记录的偏移量。通过对比这个值与上面 slave 列表中的 offset 字段,其差值就是 slave 的延迟偏移量。offset 的是执行命令的字节数,而并不是实际数据占用空间的大小。如果还没有 slave 连接,那么这个 offset 是不会记录的。并且,这里是只会处理写命令,对读命令是不会增加这个 offset 值。无论客户端使用的是行模式(PROTO_REQ_INLINE),还是块模式(PROTO_REQ_MULTIBULK),这些命令会重新格式化为块模式保存进 backlog,并按这种格式计算 offset 值。
repl_backlog_active: backlog 是否已激活。 当一旦有slave连接成功,master 就会创建 server.repl_backlog ,即使后续所有slave 都断开,repl_backlog 也会保持一段时间。
repl_backlog_size: backlog 的大小,默认值是1MB(1024*1024),可在配置文件中设置 (repl-backlog-size)
repl_backlog_first_byte_offset: backlog 第一个字节的 offset 。在内核中是 server.repl_backlog_off (server.repl_backlog_off = server.master_repl_offset - server.repl_backlog_histlen + 1;)
repl_backlog_histlen: backlog 的实际长度,最大为 repl_backlog_size 。实际上,在 backlog 激活后,随着写命令的增多,repl_backlog_histlen 增加到与 repl_backlog_size 相等时,将不会再次变化。
slave 节点专属的字段
master_host: master 节点的ip
master_port: master 节点的port
master_link_status: 与master节点的tcp 连接状态,可能的值有2个:up / down 。(server.repl_state == REPL_STATE_CONNECTED 时为 up ,其余状态都为 down)
master_last_io_seconds_ago: 最后一次IO到现在的时间,单位为:秒。计算方式是:server.unixtime - server.master->lastinteraction,如果与master断开则为 -1 。
master_sync_in_progress: 是否在传输状态 (REPL_STATE_TRANSFER)
slave_repl_offset: 复制偏移量(在内核中是 server.master->reploff )
slave_priority: 优先级,可在配置文件配置。(在sentinel 模式中,如果master 故障,将根据slave_priority值越小则优先被提升,进而执行故障转移)
slave_read_only: 是否只读
master_sync_left_bytes: 传输剩余字节数 (当 server.repl_state == REPL_STATE_TRANSFER 时才会显示此项)
master_sync_last_io_seconds_ago: 最后一次传输IO到现在的时间,单位为:秒(当 server.repl_state == REPL_STATE_TRANSFER 时才会显示此项),计算方式是:server.unixtime - server.repl_transfer_lastio,注意要与 master_last_io_seconds_ago 区分。
master_link_down_since_seconds: 与master断开的时间(当 server.repl_state != REPL_STATE_CONNECTED 时才会显示此项 )
对于这么多的字段,如果不仔细去琢磨的话,对于上面的解释肯定会有不少疑问。特别是有些看上去相似的字段其含义具体有啥区别呢?带着疑问一起来分析吧。
首先,我们需要看看有几种消息(也称为RPC)类型。实际上消息类型只有一种,就是发送普通的命令,并没有为 Master/Slave 机制添加额外的消息类型,但是为其添加了额外的命令来支持。slave -> master 的命令有3类:SLAVEOF、SYNC、REPLCONF。master -> slave 的命令有2类:PING、REPLCONF。如下:
client -> slave:
SLAVEOF <master-ip> <master-port> SLAVEOF NO ONE
slave -> master:
PING (一次) SYNC PSYNC <replid> <offset> REPLCONF listening-port <value> REPLCONF ip-address <value> REPLCONF capa [eof | psync2] REPLCONF ack <offset>
master -> slave:
PING(定时) REPLCONF GETACK *
之前我们提到 INFO 命令输出结果,其中有些字段与节点状态有关。master 、slave 节点分别使用不同的状态标记在各自的视角下其对应的节点所处在哪个阶段。
master 视角 :
SLAVE_STATE_WAIT_BGSAVE_START SLAVE_STATE_WAIT_BGSAVE_END SLAVE_STATE_SEND_BULK SLAVE_STATE_ONLINE
slave 视角 :
REPL_STATE_NONE REPL_STATE_CONNECT REPL_STATE_CONNECTING /* --- Handshake states, must be ordered --- */ REPL_STATE_RECEIVE_PONG REPL_STATE_SEND_AUTH REPL_STATE_RECEIVE_AUTH REPL_STATE_SEND_PORT REPL_STATE_RECEIVE_PORT REPL_STATE_SEND_IP REPL_STATE_RECEIVE_IP REPL_STATE_SEND_CAPA REPL_STATE_RECEIVE_CAPA REPL_STATE_SEND_PSYNC REPL_STATE_RECEIVE_PSYNC /* --- End of handshake states --- */ REPL_STATE_TRANSFER REPL_STATE_CONNECTED
但是,如果你不了解内部原理,那么会发现这些信息很难关联起来。我们接下来的介绍将会把上面提到的每个字段都进行描述,包括使用场景、何时赋值、何时更新等等。大致概括为这么几部分:
1. 通讯流程
a. 使用 redis-cli 工具连接到 slave 节点,然后执行命令 SLAVEOF <master-ip> <master-port> ,此时会马上成功返回,而不是等待与 master 连接成功之后再返回。在这个命令中,有这么一些逻辑:
1> 初始化一些相关变量
server.masterhost = sdsnew(ip) server.masterport = port server.repl_state = REPL_STATE_CONNECT
2> 如果这个 slave 现在已经有子slave(subslave),那么断开与subslave的连接,让其超时后重新同步。
b. 如果我们要取消复制,只要在slave节点上执行命令 SLAVEOF NO ONE 即可。这一步的执行时机根据需要进行。在这个命令中,有这么一些逻辑:
1> 重置一些相关变量
server.masterhost = NULL server.repl_state = REPL_STATE_NONE
2> 变更 replid,把当前的 server.replid 复制给 server.replid2,并且重置 server.replid为40字节的随机字符串。
3> 释放 server.master 。server.master 是一个 client 类型结构。对应的在 master 节点中也会有 server.slaves 列表中也是记录的与之连接的 slave ,其也是 client 类型结构。
c. 当 a 步骤执行完之后,由后台定时任务根据master-ip / master-port 去连接其 master 节点。大致有这么些逻辑:
1> 创建TCP连接,同时设置读写事件处理函数 syncWithMaster 。
2> 重置相关变量
server.repl_transfer_lastio = server.unixtime; server.repl_transfer_s = fd; server.repl_state = REPL_STATE_CONNECTING;
d. 当连接成功创建之后,就是由 slave 发送一些命令给 master 做一些初步的检测验证工作。
1> slave 向 master 发送 PING ,状态到达 REPL_STATE_RECEIVE_PONG
2> slave 接收 PONG 回复,状态到达 REPL_STATE_SEND_AUTH
3> 如果有配置 masterauth,则 slave 向 master 发送 AUTH,状态到达 REPL_STATE_RECEIVE_AUTH。如果没有配置,直接进入 REPL_STATE_SEND_PORT
4> slave 向 master 发送 REPLCONF listening-port <port> ,状态到达 REPL_STATE_RECEIVE_PORT。如果有配置 announce_port 则使用 announce_port ,否则使用 server.port 。announce_port的设计是为了支持DOCKER/NAT 网络环境。
5> slave 接收 REPLCONF 回复,状态到达 REPL_STATE_SEND_IP
6> 如果有配置 announce_ip 则向 maste 发送 REPLCONF ip-address <announce_ip>,状态到达 REPL_STATE_RECEIVE_IP。如果没有配置 announce_ip ,直接进入 REPL_STATE_SEND_CAPA 状态。announce_ip 的设计也是为了支持 DOCKER/NAT 网络环境。
7> slave 接收 REPLCONF 回复,状态到达 REPL_STATE_SEND_CAPA
8> slave 向 master 发送 REPLCONF capa eof capa psync2 ,状态到达 REPL_STATE_RECEIVE_CAPA 。告诉 master,支持哪些处理能力,这里代表支持 EOF (supports EOF-style RDB transfer for diskless replication) 与 PSYNC2(supports PSYNC v2, so understands +CONTINUE <new repl ID>)。
9> slave 接收 REPLCONF 回复,状态到达 REPL_STATE_SEND_PSYNC
10> slave 向 master 发送 PSYNC <replid> <offset> ,状态到达 REPL_STATE_RECEIVE_PSYNC。如果之前有跟随的Master,将会在 server.cached_master 中保存有 server.master 的副本。在master/slave 连接复制中断(非主动,即不是使用 SLAVEOF NO ONE)时,server.master 会释放,而其副本 server.cached_master 仍将会保留,其作用也主要在此,为了支持 PSYNC 。由于不知道之前连接的 master 是否是同一个,或者数据是否一致,把 replid / offset 发送给 master,master 会进行验证,然后回复对应的结果。如果没有 server.cached_master ,则只能进行全量同步了,发送的命令是这样的: PSYNC ? -1 。
11> slave 接收 PSYNC 回复。PSYNC 全称为部分再同步 (partial resynchronization),也是作为master/slave间复制的最关键的部分,那么slave将对每一种可能的回复都将进行处理。
PSYNC 回复大致有4种类型:
PSYNC_FULLRESYNC 全量同步,对应的回复是:+FULLRESYNC <replid> <offset>。
有3种可能,第一,offset不匹配,即与master 节点断开时间太长,master节点backlog里已经没有我们需要的offset对应的数据,如果不全量同步,就会有master/slave数据不一致问题,第二, replid 不匹配,可能是发生了重启或者角色的变更,如果不全量同步,也可能会产生数据不一致的问题。第三,replid 与 offset 都不匹配。同时slave 节点也会更新2个变量,释放 server.cached_master。如下:
server.master_replid = replid server.master_initial_offset = offset server.cached_master = NULL
PSYNC_CONTINUE 继续,对应的回复是:+CONTINUE。
说明 PSYNC 命令中的 replid 与对应的 master replid 相同,offset 在对应的 master 的 backlog 记录范围内。那么接下来就只同步增量数据啦,这也是部分重同步期望的回复结果。
通过调用 replicationResurrectCachedMaster ,使用 server.cached_master 相关字段初始化新的 server.master ,添加到 client 列表,注册读事件处理函数 readQueryFromClient,注册写事件处理函数 sendReplyToClient。 通过接收处理 master 转发来的redis 命令来保持数据同步。 至此 slave 将进入如同接收普通的客户端命令般标准处理模式。
相关变量更新:
server.master = server.cached_master server.cached_master = NULL server.master->fd = newfd server.master->flags &= ~(CLIENT_CLOSE_AFTER_REPLY|CLIENT_CLOSE_ASAP) server.master->authenticated = 1 server.master->lastinteraction = server.unixtime server.repl_state = REPL_STATE_CONNECTED server.repl_down_since = 0
如果 backlog 未创建,将初始化 backlog ,用于与其子slave 同步(subslave)。
PSYNC_NOT_SUPPORTED 不支持PSYNC,对应的回复是:-ERR error_msg。
可能 master 节点版本过老,还不支持这个 PSYNC 命令,那么接下来 slave 将尝试发送低版本可能支持的命令:SYNC ,进行全量同步。
PSYNC_TRY_LATER 稍后重试,对应的回复是:-NOMASTERLINK(master 节点不是顶级 master 节点,并且没有与其上级的master 连接完成) 或者 -LOADING ( master 节点在加载数据)。这时状态也会回退到 REPL_STATE_CONNECT,表示需要重新开始一次连接与握手操作。
当与 master 确认进行全量同步之后,slave就进入了新的状态 REPL_STATE_TRANSFER ,创建临时rdb文件(fd = dfd),并且注册读取事件处理函数 readSyncBulkPayload 。相关的变量如下:
server.repl_state = REPL_STATE_TRANSFER; server.repl_transfer_size = -1; server.repl_transfer_read = 0; server.repl_transfer_last_fsync_off = 0; server.repl_transfer_fd = dfd; server.repl_transfer_lastio = server.unixtime; server.repl_transfer_tmpfile = zstrdup(tmpfile);
12> 接着,我们来看看接收现有数据的处理过程(readSyncBulkPayload)。
当在上一步到达 PSYNC_FULLRESYNC 或者 PSYNC_NOT_SUPPORTED 模式之后,那么接下来,将注册读事件处理函数 readSyncBulkPayload,对现有数据的全量同步。支持2种格式:第一种,$<count> \r\n<bulkdata...> 格式
这种是 master 把内存数据保存为 rdb 文件,其中 count 为文件的字节大小,bulkddata 为文件内容,我们称这种为非usemark模式。成功读取之后的 count 字节之后,认为数据读取完毕。来初始化的变量为:
usemark=0 server.repl_transfer_size = count
第二种,$EOF:<40 bytes delimiter>\r\n<bulkdata...><40 bytes delimiter>
这种是使用于 master 的 diskless(无盘复制)模式,即直接把内存数据通过网络发送给 slave ,没有保存为 rdb 文件的过程,所以不知道字节大小,只能使用特殊标记来处理,我们称这种为 usemark 模式,即 usermark=1。通过对比 delimiter 与 每次读取到的最后40个字节比较,如果相同则表明数据读取完毕 。初始化的变量为:
usemark=1 eofmark=delimiter server.repl_transfer_size = 0
读到的内容将写入临时rdb文件。即使现有数据比较大,slave 也会在每次事件处理中读取一小部分,然后等待到达下次读事件再处理。每次读处理完之后,会更新这几个变量:
server.repl_transfer_lastio = server.unixtime server.repl_transfer_read += nread
这样,我们就能够通过 INFO 命令查看到同步进度,是不是很酷。。如非如此设计,将可能在数据同步过程中,slave 将无法处理任何命令,你也就只能等待最终结果。如果数据比较小还行,一旦数据量过大,你会发现这个设计很有用。
在每次写入超过 8MB (REPL_MAX_WRITTEN_BEFORE_FSYNC)字节的数据到临时rdb文件时,将强制刷到真正的磁盘上,避免过大的内存缓冲刷到磁盘时产生的巨大延迟。
当经过N次的读事件的处理,最后如果成功读取完相应数据,则进入下面的流程。
i. 重命名临时rdb文件为slave配置的rdb文件名
ii. 清空现有内存数据(emptyDB)
iii. 删除读事件
iv. 加载rdb文件
v. 创建 server.master
vi. 进入 REPL_STATE_CONNECTED 状态
vii. 创建 backlog
相关的变量更新:
server.master->reploff = server.master_initial_offset server.master->read_reploff = server.master->reploff server.master->replid = server.master_replid server.repl_state = REPL_STATE_CONNECTED server.repl_down_since = 0 server.replid = server.master->replid server.master_repl_offset = server.master->reploff
另外,在调用 createClient 创建 server.master 时,也会注册读事件处理函数 readQueryFromClient 。至此,进入标准模式,将通过 readQueryFromClient 处理 master 发送来的命令。在之前的过程是使用同步模式,即通过当前的函数中阻塞等待消息回复。两种模式对应的处理函数不同,执行逻辑也是不同的,要做好区分。
13> 其实,除了上面这些主逻辑之外,还有少许关于复制(replication)的内容在网络模块 (redis/networking.c)中。
在整个master/slave 建立连接(握手)的过程执行期间,slave 还是可以接受其他标准客户端的请求,并进行处理,其处理函数是 readQueryFromClient 。我们上面说过 master 也是slave的一个客户端,但是在成为 REPL_STATE_CONNECTED 之后才真正把 master 发送过来的消息按照标准模式处理 (readQueryFromClient)。
在获取到客户端请求命令之后,实际主逻辑执行之前,readQueryFromClient 函数会记录 lastinteraction 与 read_reploff,如下:
c->lastinteraction = server.unixtime; if (c->flags & CLIENT_MASTER) c->read_reploff += nread;
这里的 c 是指客户端对象,如果是 master 发送来的命令,c 即为 server.master , 如果是 slave 发送来的命令,c 即为 server.slaves 列表中的其中一个。我们看到,无论是 master 发送给 slave ,还是 slave 发送给 master 都会更新 lastinteraction 。但是只有 master 发送给 slave 消息时,更新读取到的复制偏移量,即 read_reploff 。
默认,接收到客户端消息之后,会把消息内容缓冲到 c->querybuf,当 slave 收到 master 消息时会复制一份到新的缓冲 c->pending_querybuf,用于子slave的复制。
在处理完整个命令的具体逻辑(processCommand)之后,如果客户端是 master ,则更新偏移量 c->reploff :
if (c->flags & CLIENT_MASTER && !(c->flags & CLIENT_MULTI)) {
/* Update the applied replication offset of our master. */
c->reploff = c->read_reploff - sdslen(c->querybuf) + c->qb_pos;
}
14> slave 向 master 发送 REPLCONF ack <offset>
为了在 master 视角可以查询所有 slave 的同步情况,在建立连接成功(Slave 处于 REPL_STATE_CONNECTED 状态)之后,由各个 slave 来定时上报其已经到达的 offset (接收数据,并处理完毕)。每秒发送一次。
15> 如果 slave 接收到 master 发送的 REPLCONF getack,则同样回复 REPLCONF ack <offset> 消息。
接下来,我们开始分析整个过程在 master 节点上是如何处理的?
1> 接收 slave 发送的 PING 消息
这一步仅仅是回复 +PONG ,没有其他额外处理。slave 发送 PING 消息,只是为了测试与 master 节点是否存在或可用。2> 接收slave 发送的 AUTH 消息
验证口令。由于是把 slave 当作了 client 来对待,所以可以使用一套 auth 模式来检验允许哪些 slave 连接,很好的解决了数据安全性的问题。3> 接收 slave 发送的 listening-port
c->slave_listening_port = port
4> 接收 slave 发送的 ip-address
c->slave_ip = ip
5> 接收 slave 发送的 capa
如果 slave 支持 eof ,则: c->slave_capa |= SLAVE_CAPA_EOF 如果 slave 支持 psync2,则: c->slave_capa |= SLAVE_CAPA_PSYNC2
6> 接收 slave 发送的 ack
c->repl_ack_off = offset c->repl_ack_time = server.unixtime
如果是 diskless 模式,已是 SLAVE_STATE_ONLINE 状态,则调用 putSlaveOnline 切换到正在的在线状态 ,其中更新的变量如下:
slave->replstate = SLAVE_STATE_ONLINE slave->repl_put_online_on_ack = 0 slave->repl_ack_time = server.unixtime
其中也会注册标准的客户端写事件处理函数 sendReplyToClient 。
7> 接收 slave 发送的 PSYNC <replid> <offset>
如果是 redis 2.8 版本之前,应该是不支持 PSYNC ,所以就会直接回复一个错误(不支持此命令)。如果支持 PSYNC ,那么 master 会对 replid 与 offset 进行验证。
首先,验证 replid 。master 保存有 2 个 replid ,分别是 server.replid (当前的replid)与 server.replid2(之前的replid),如果这2个 replid 与上面接收到的 replid (为了区分,我们称为 psync_replid)都不同,则认定为需要全量重同步(need full resync)。如果 psync_replid 与 server.replid2 相同,但是 psync_offset > server.second_replid_offset ,则也认为 slave 与 master 的之间的数据可能不一致,因为如果 slave 之前就是一直正常跟随这个 master ,那么其自身的 offset 一定是小于 master 的 offset 。当然,如果 psync_replid 等于 ?时,也直接认定需要全量重同步。
其次,当 replid 匹配时,接着验证 offset。master 会把从客户端接收的命令重新格式化之后保存到 backlog 中,backlog 是一个循环利用的固定大小的缓冲。所有只有上面接收到的 offset (为了区分,我们称为 psync_offset)在这个backlog 数据的范围之内才可行。backlog 的起始 offset 为 server.repl_backlog_off,backlog的最大 offset 为 server.repl_backlog_off + server.repl_backlog_histlen 。如果 psync_offset 小于 backlog 起始值,也就是 backlog 中旧的内容已经被新的数据冲掉, 则说明 slave 与 master 断开时间过长,必须要重新全量同步。如果 psync_offset 大于 backlog 的最大值,则说明这个 slave/master 的同步发生了异常,如之前所述,正常的 slave 是的 offset 值是小于等于 master 的offset值。
那么,最终有2个结果,如果 psync_replid 与 psync_offset 都验证通过,则认为可以继续增量同步,否则将需要全量重同步。
8> 继续增量同步
给 slave 发送回复 +CONTINUE ,如果是 slave 支持 PSYNC2 ,则会同时会携带当前的replid,回复内容是: +CONTINUE <replid>,这里的replid 是 server.replid。接着,根据 psync_offset 计算与 slave 的增量数据,放入回复缓冲(c->buf)中。要注意区分,上面的 CONTINUE 是使用同步方式立即发送的,这个是放入缓冲,等待下次写事件触发。为什么这么做,后面讲详细分析。
同时,也会更新一些非常关键的变量:
c->flags |= CLIENT_SLAVE; c->replstate = SLAVE_STATE_ONLINE; c->repl_ack_time = server.unixtime; c->repl_put_online_on_ack = 0; listAddNodeTail(server.slaves,c);
至此,这个 slave 进入了 SLAVE_STATE_ONLINE 状态,并且进入了 master 保存的 slave 列表(server.slaves)。
9> 全量重同步
如果接收到的不是 PSYNC 命令,而是 SYNC,则标记 c->flags |= CLIENT_PRE_PSYNC,也将开启全量重同步。进入全量重同步前,先会更新一些变量:
c->replstate = SLAVE_STATE_WAIT_BGSAVE_START c->repldbfd = -1 c->flags |= CLIENT_SLAVE listAddNodeTail(server.slaves,c)
可以看到 slave 已经添加到 server.slaves 列表,但是状态是 SLAVE_STATE_WAIT_BGSAVE_START 。
之前有提到,在新版本中支持2种方式,一种是rdb文件模式(姑且这么称呼吧,因为需要先保存为rdb形式的文件),另一种是disless 模式(不需要先保存rdb文件,也就是对应slave要支持 EOF )。
当slave 同时支持这2种模式之后,具体使用哪种取决于master的配置。如果开启 repl-diskless-sync 则使用 diskless 模式,默认是关闭。
对应有2个选项:
repl-diskless-sync (默认值:0)
repl-diskless-sync-delay (模式值:5 ,单位:秒)
rdb文件模式是master 进行快照操作,把内存数据保存到 rdb 文件,然后把 rdb 文件通过网络传输给 slave,然后slave加载这个rdb文件数据到内存。diskless模式是master直接把内存数据通过网络传输给slave,slave 加载到内存中。两者都是通过其父进程fock一个子进程的方式执行,不会阻塞影响master的正常运行,也就是说这时master可以继续对外提供服务。fock 的这个子进程称为 rdb 子进程(方便下面描述,其对应代码是 server.rdb_child_pid != -1)
当在添加一个slave 时,如果这个时候正好有其他的slave 也在加入,并且已经 fock了rdb子进程执行,那么新加入的slave的处理过程与之有些差异,但是结果是等同的。可以分为4种情况:
第一,如果是 rdb文件模式,未有开启的rdb子进程。
如果有 aof 进程在运行,那么接下来的这些操作也将延后执行,最终由周期性函数 replicaitonCron 调用 startBgsaveForReplication 开始一次 BGSAVE 操作。
开启一个 rdbSaveBackground 操作,保存内存快照到 rdb 文件。并调用 replicationSetupSlaveForFullResync 函数,更新变量如下:slave->psync_initial_offset = offset;
slave->replstate = SLAVE_STATE_WAIT_BGSAVE_END;
最后给 Slave 回复 +FULLRESYNC <server.replid> <offset>,告诉slave,replid与初始offset,并准备接收 rdb 文件数据。
第二,如果是 diskless 模式,未有开启的 rdb 子进程。
会延迟执行,根据 repl-diskless-sync-delay 配置,到达延迟时间后由周期性函数 replicationCron 调用执行。在replicationCron中也是调用 startBgsaveForReplication 开始一次 BGSAVE 操作。同样通过调用 replicationSetupSlaveForFullResync 函数更新状态及初始偏移量,之前有提,此处省略。如果有多个 slave 都在 SLAVE_STATE_WAIT_BGSAVE_START ,那么在一个rdb子进程中同时处理。
第三,如果是 rdb 文件模式,有开启 rdb 子进程。
当一个slave 已经进入 SLAVE_STATE_WAIT_BGSAVE_END 状态,在这期间新加入的 slave 将不开启新的 rdb 子进程,而是等待之前的 BGSAVE 操作完成,并且利用其保存的最新的 rdb 文件发送给 slave 节点。那么就需要找到那个之前进入 SLAVE_STATE_WAIT_BGSAVE_END 状态的 slave ,复制其输出缓冲 c->buf 与 c->reply 到新的 slave。同时调用 replicationSetupSlaveForFullResync 更新状态及初始偏移量,之前有提,此处省略。
为什么要复制输出缓冲?
因为,在整个过程 master 一直是可用状态,在 fork 开启了 rdb 子进程之后,如果在master 上新产生数据时,rdb 子进程是无法获取到的。master 会把新的客户端写命令放入输出缓冲中,直到成为 SLAVE_STATE_ONLINE 时才会真正发送给 slave,在这个期间一直会在输出缓冲中积累。正好利用这一特性,可以通过复制输出缓冲的方式可以节省 fork rdb 子进程的开销。
为什么要复制 offset ?
offset 代表数据的复制的偏移量,也即代表了fork那个时间点 master 的offset,因为使用相同的rdb文件同步给 slave,所以就应该使用相同的初始 offset 。
为什么要在输出缓冲中积累?
首先,旧数据还没有复制给slave节点,所以时序上来说,应该先积累,等旧数据复制完成之后再把新增数据发送给 slave。其次,还有一个 backlog 好像也可以实现这个功能,但应该是由于 backlog是固定大小,如果BGSAVE期间写命令过多,超过 backlog 的大小之后,造成的数据丢失,这样复制给 slave 就不妥了。
第四,如果是 diskless 模式,有开启 rdb 子进程。
为了合理利用资源,如果是 diskless 模式,则会延迟执行。如果短时间有多个 slave 同时加入的话,fork 一个 rdb 子进程即可。
至此,slave 就进入了 SLAVE_STATE_WAIT_BGSAVE_END 状态。10> 发送rdb文件到 slave
其实这一小节的内容应该属于上节的范畴,但是为了流程上更加容易理解,我们单独来描述。
不管是rdb文件模式,还是diskless模式,都是fork 一个 rdb 子进程来处理。当主进程收到子进程执行完毕的消息之后,调用 backgroundSaveDoneHandler 来处理后续的过程。
对于 diskless 模式,通过pipe 的方式(server.rdb_pipe_read_result_from_child)读取子进程处理的结果,如果有错误,则通过调用 freeClient 释放连接。freeClient 内部会把这个 slave 从 server.slaves 中移除掉。如果没有检测到错误,则更新变量:
slave->replstate = SLAVE_STATE_ONLINE; slave->repl_put_online_on_ack = 1; slave->repl_ack_time = server.unixtime;
但是,此时输出缓冲还是一直在积累,直到收到 slave 发来的 REPLCONF ack 消息。收到 slave 发来的 ack 消息说明在 slave 视角其与master的连接已进入完备状态(REPL_STATE_CONNECTED),所以此时 master 也通过调用 putSlaveOnline 来更新 slave->repl_put_online_on_ack = 0 使其slave 的输出缓冲阻塞取消。
对于rdb文件模式,此时只是 rdb 文件保存完毕。删除之前的写事件处理,增加新的写事件处理函数 sendBulkToSlave 。同时更新变量:
slave->repldboff = 0; slave->repldbsize = buf.st_size; slave->replstate = SLAVE_STATE_SEND_BULK;
通过事件调用 sendBulkToSlave ,每次发送 16 K 数据。当发送完毕之后,删除写事件处理函数 sendBulkToSlave。同时通过 putSlaveOnline 注册新的客户端输出标准处理函数 sendReplyToClient,及更新:
slave->replstate = SLAVE_STATE_ONLINE; slave->repl_put_online_on_ack = 0; slave->repl_ack_time = server.unixtime;
至此,slave 进入了最终完备状态 SLAVE_STATE_ONLINE 。
2. 数据同步
上面使用大量的篇幅介绍了一个新的 slave 与 master 之间的复制过程,涉及的细节点过多,我们在这里做一个总结吧。首先,复制模式根据具体环境与配置,有2种可能的方式:rdb文件模式、diskless模式。如果 slave 之前有跟随 master,则尝试一次部分重同步(PSYNC),如果检验没通过,则开启一次全量重同步(FULLRESYNC)。在这个过程中,master 还可以正常对外提供服务,会把新的写命令放入一个输出缓冲中,等已有数据复制完成之后,再把这个缓冲中的命令发送给相应的 slave。当在 master 的视角 slave 进入 SLAVE_STATE_ONLINE,接收到客户端的写命令时,也是通过输出缓冲结合写事件处理函数sendReplyToClient 发送给 slave。如果是 diskless 模式,需要收到 ack 消息时才真正释放输出缓冲。
3. 偏移量 (offset)
a. 当有 slave 连接到 master 时,master 开启 BGSAVE ,并且将从把新的写命令通过 feedReplicationBacklog 放入输出缓冲,同时增加 server.master_repl_offset ,增加值为重新格式化后的命令命令字符串字节数。那么在master启动一段时间之后,如果没有 slave 则这个值一直是 0 ,知道有第一个 slave 连接时这个值才变化。
b. slave 与master 进行了全量重同步之后,master 通过 +FULLRESYNC 回复告诉其初始的 offset,然后再根据接收到的 master 转发的命令的字节长度增加这个 offset。这个offset 保存在 slave 中的 server.master->reploff 。
c. slave 视角下,连接处于正常状态(CONNECTED)时,会每隔1秒发送一次 REPLCONF ack <offset> 消息给master。这样在2种不同的视角下都能看到 slave 的复制进度。在master视角下能看到所有slave的复制情况,对于管理员非常方便。
4. 定时检测机制
通过 replicationCron 来执行一些定时检查
a. 如果长时间处于连接中状态 (REPL_STATE_CONNECTING),超时则取消,调用 cancelReplicationHandshake 释放相关资源。
b. 如果长时间处于传输中状态 (REPL_STATE_TRANSFER),超时则取消,调用 cancelReplicationHandshake 释放相关资源。
c. 如果长时间处于连接成功状态(REPL_STATE_CONNECTED),超时则取消,调用 freeClient 释放相关资源。
d. 上面这些过程,都在slave 视角执行,并且都会把状态回退到连接初始状态(REPL_STATE_CONNECT),以便重试。
e. 如果处于 REPL_STATE_CONNECT,则尝试与 master 连接。
f. 当与master成功连接后,每隔1秒向master 发送 ack 回复,并带有 offset。(成功连接指 server.master已被初始化,其实此时状态也就到了 REPL_STATE_CONNECTED )
g. master 定期向 slave 发送 PING 消息,间隔时间通过repl-ping-replica-period 来配置,默认是10(单位为秒)
h. 当在master视角下,Slave 处于 BGSAVE 的一系列状态时,通过同步方式发送一个 \n ,相当于PING消息给slave。因为这些阶段可能比较耗时,而输出缓冲也处于暂停输出状态,通过这种方式来告诉slave,其master还在线,阻止其slave 触发超时处理机制。
i. 前面的 4 步,都是在slave 视角下处理超时的情况,这步将有 master 来处理超时。通过最新接受到的 ack 的时间 (slave->repl_ack_time)与超时时间 server.repl_timeout (配置选项repl-timeout ,默认值是60,单位为秒)来判断。
j. 如果所有的 slave 都断开,并且超过一定的时间,则 master 释放 backlog 。超时配置选项 repl-backlog-ttl,默认值为 1800,单位为秒,也就是 1小时。
5. backlog
a. backlog 固定大小,有其对应的超时时间。
b. 循环利用的缓冲(circular buffer)
c. 在MySQL中也有使用类似的缓冲机制。
idx|---------------------------|----------------|
offset
start end
d. 使用与PSYNC(部分重同步),避免短暂的网络抖动,而造成所有slave进行全同步,导致master负载过高。
6. server.master 与 server.cached_master ?
a. 当在调用freeClient释放 server.master时,为了后期执行 PSYNC ,所以会保留一个副本 server.cached_master ,记录之前的复制的信息 replid 、reploff 。
b. 当slave 尝试与 master 进行 PSYNC,但是master回复 +FULLRESYNC (要求全量重同步) 或者 -ERR (不支持PSYNC)是会调用 replicationDiscardCachedMaster 移除 server.cached_master。
c. 另外,如果手动执行 SLAVEOF NO ONE 取消复制关系时,也会调用 replicationDiscardCachedMaster 移除 server.cached_master 。
7. server.replid 与 server.replid2 ?
a. 通过手动执行 SLAVEOF NO ONE 取消复制关系时,slave 会提升会 master,这时候会调用 shiftReplicationId 来记录之前的 server.replid 为 server.replid2,并且记录 server.second_replid_offset = server.master_repl_offset+1。同时调用 changeReplicationId 生成新的 server.replid。
b. 当 slave 与 master 连接时,发现其master返回的 replid 与自身不同时,会更新自身的 server.replid 为master 的 replid,并且移除 server.replid2。比如,在执行全量重同步之后,或者是在执行部分重同步时。
c. 当 master 没有 slave 跟随,超过 backlog 的超时时间时,会移除 backlog,此时也是会调用 changeReplicationId 生成新的 server.replid,同时会调用 clearReplicationId2 移除 server.replid2 。
d. 这么设计的目的就是为了服务层级复制架构。比如 master -> slave -> subslave 这样的架构,在正常复制时,这3个节点的 server.replid 都是相同的,代表一个复制组。当断开 master -> slave 的复制时,slave 就会提升为 master,此时为了让 subslave 继续保持与slave的复制关系,不进行全量重同步,在slave 中保存了一个 server.replid 的副本。slave 角色发生变化时会断开所有 subslave 的连接,这时候 subslave 就会重新尝试进行PSYNC,最终省去了一次因slave角色发生变化而导致的全量重同步。
8. 可配置项
replicaof replica-announce-ip masterauth replica-serve-stale-data replica-read-only replica-ignore-maxmemory repl-ping-replica-period repl-timeout repl-backlog-size repl-backlog-ttl repl-disable-tcp-nodelay repl-diskless-sync repl-diskless-sync-delay replica-priority min-replicas-to-write min-replicas-max-lag
常用配置项在上面都已提到,如想谅解更详细的使用场景,可以参看安装包中的完整配置文件中注释。
附一张大致流程图: