Redis Sentinel 高可用原理
现在 B/S C/S 架构的软件系统设计时,我们通常需要把服务端设计为高可用系统,比如 3个9(99.9%),4个9(99.99%),5个9(99.999%)。这是由于随着用户请求量的增加,服务端系统需要处理的事务会增加,进而可能会导致服务端系统无法快速、正确响应用户请求,使得用户体验变得非常糟糕。最终可能会使得用户流失,对广告、会员等这部分收入产生严重影响。另外,Redis作为基础组件,一旦出现故障,可能会使得好多业务出现异常。因此高可用是非常有必要的,也是一个软件开发者应该具备的基本能力之一。
软件系统的高可用有2个层次,第一,软件系统自身缺陷较少,或者说不会发生故障;第二,在发生故障时可以自动重启恢复服务或者使用备机来转移这部分流量,进而使得对于访问这个服务的用户来说,根本感知不到服务端出现异常。我们应该尽力做好第一项,以此保证服务的长期可用性,但是天有不测风云,人有旦夕祸福,保证服务100%不出异常是不可能的。当故障发生时,我们需要以最快的时间恢复服务,减少影响用户使用的时间,因此就需要一种机制来自动恢复服务。
目前Redis已经成为家喻户晓的基础组件,应用在众多大型的系统中。其中Redis Sentinel 用来实现Redis高可用。在一般的架构部署中,sentinel 最少应部署3个节点,实现自身高可用,并且为Redis的Master/Slave架构提供投票选举。Redis还有其他高可用方案,比如Redis Cluster,这里只介绍Sentinel 的实现原理。在Sentinel模式中,有三中角色,Sentinel/Master/Slave,要保证整体集群高可用就需要保证这3个角色高可用,次之也要保证Sentinel与Master高可用。一个Sentinel组可以同时维护多个Master,一个Master下可以有N个Slave。各个Master之间没有直接关系,单个Master只与自己的Slave进行连接。因此我们就以在一个Sentinel组中只有一个Master和两个Slave为例进行阐述其原理。这时,可能还是有点复杂,因为在其中有可能任何一个角色的任何节点都可能发生故障,可能让整个文章逻辑非常混乱,因此我们的主流程还是假设只有Master发生故障,Sentinel全部正常,Slave也全部正常。然而Master发生故障可能也有两种情况,其一,自身故障,其二,被设置为了Slave,这两种情况下,客户端都是无法正常连接执行所有操作,因此这里统一称为发生故障。这么下来的话,故障分为这么几种及这几种的任意组合。
⑥Slave故障(追随了新的Master)
所以,我们先假设④Master故障(自身故障),其他节点全部正常,分为三部分,故障检测、故障发现、故障转移。
第一,故障检测
第二,故障发现
第三,故障转移
从上面的分析我们可以看到,S1认为M1发生了故障,并且这个已经征得多数Sentinel同意,所以就认为M1发生了故障。那么接着就是故障转移,有多个Sentinel,究竟谁来这行这个执行这个故障转移呢,如果让多个Sentinel合作执行这个转移,可能会让这个过程因为分工问题而复杂化,这不符合Redis的理念(简洁、易懂、高效)。因此每个Sentinel都会先通过向其他Sentinel进行拉票,选举出其中一个Sentinel来执行故障转移操作。
1. 选举Leader(failover_state:SENTINEL_FAILOVER_STATE_WAIT_START)
在极限情况下,当M1出现故障时,这些Sentinel都在几乎相同的时间内检测到,并且得到了其他其他Sentinel的同意(认为M1确实是发送了故障),这时可能都在争取故障转移的权利,导致这个投票结果不合理(没有大多数选票选择同一个Sentinel),所以需要一个机制来规避这种情况。在Sentinel组内,每个Sentinel都有各自的Id(run_id),还有一个纪元(epoch),也可以理解为全局版本号。在正常情况下,一个Sentinel组内每个Sentinel的run_id不同,但是epoch相同。当每个Sentinel都检测到M1发生故障了,各自向其他Sentinel发出拉票请求,希望给自己投票,获得多数票者,开始故障转移。拉票请求中携带的信息中包含当前Sentinel的run_id与新的epoch(epoch+1),我们给他们起一个别名,方便在区分,run_id为req_runid,epoch为req_epoch。接收到拉票请求的Sentinel会进行投票操作。每个Sentinel都会收到其他Sentinel的拉票请求,这里没有特权,大家都是公平的。每个Sentinel内部结构的Sentinel.masters.M1中记录着当前的leader与leader_epoch,接收到拉票请求的Sentinel会进行对比,如果 leader_epoch < req_epoch ,则更新leader为req_runid,leader_epoch为req_epoch,同时如果当前 epoch < req_epoch,也会更新sentinel.current_epoch为req_epoch,最后回复 leader 与 leader_epoch。当收到第二个Sentinel的拉票请求时,由于在同一个epoch周期,所以req_epoch相同,则不会重置 leader与leader_epoch的值,直接返回上一步重置完的leader与leader_epoch。概况为一句话就是,在一个epoch周期,每个Sentinel只给一个Sentinel投票,这样缓解了各个Sentinel彼此拉票导致问题,但是仍存在某几个Sentinel选票数相同的情况,这时就是等待下一次选票,直到选出一个leader。这个leader的选票有2个要求,其一, 大于等于选票总数(所有Sentinel的总个数)/2+1,其二,大于等于 quorum(前面有提到,可在配置文件中指定) 。
2. 选择Slave(failover_state:SENTINEL_FAILOVER_STATE_SELECT_SLAVE)
在选举得到了其中一个Sentinel Leader之后,接着就是需要找一个Slave来替换故障的Master(M1)。如果有多个Slave,需要选择一个,选择过程又可以分为两步,①筛选符合预先设定规则的Slave,②在符合规则的多个Slave中,按照预设规则进行排序,最终选出一个最优的Slave。
2.1 筛选规则
2.2 排序规则
3. 取消原来的主从关系(failover_state:SENTINEL_FAILOVER_STATE_SEND_SLAVEOF_NOONE)
MULTI SLAVEOF NO ONE CONFIG REWRITE CLIENT KILL TYPE normal EXEC
MULTI/EXEC 是代表一个开始与结束,其中包含三条命令,其一,取消主从关系,其二,同步最新内存中的配置到文件中(redis.conf),防止重启后信息配置丢失的问题,其三,关闭客户端连接。
4. 等待晋升(failover_state:SENTINEL_FAILOVER_STATE_WAIT_PROMOTION)
除了会处理一些基础信息之外,还会判断节点的角色是否发生改变,比如 Master->Slave或者Slave->Master。这个阶段是等待Slave晋升为Master,所以暂且我们只关注检测到Slave->Master的情况。然后会判断这个节点是否在正常的等待晋升状态,如果是,则进入下一阶段,如果不是则重新发送Slaveof ,恢复原来的Slave->Master关系。另外,Master->Slave的情况,在这里不做任何处理,等待故障转移流程执行。Slave 角色不变,但是对于的Master的IP/PORT与原来记录的不同,并且原来的Master是健全的(sane),也是重新发送Slaveof,修正为原来的Slave->Master关系。如果发现当前Slave处理重新配置状态,则设置对应标记,下面有用到这里的逻辑。
5. 重新配置其他Slave(failover_state:SENTINEL_FAILOVER_STATE_RECONF_SLAVES)
现在晋升的Slave已经是Master角色,所以需要配置其他Slave追随新的Master,也就是这个晋升的节点(原来的Slave)。同样是遍历sentinel.masters.M1.slaves 这个列表,然后发送Slaveof命令,同时给这个Slave设置标记 SRI_RECONF_SENT,设置重新配置的开始时间 slave_reconf_sent_time。这个时间在验证超时检测中用到,这个标记在收到INFO回复时用到,也就是在4小节末尾提到的情况。其实为什么不直接检测Slaveof的回复,而要通过INFO回复来判断Slaveof是否成功执行呢?我认为有3点原因,①发送这些命令全部是异步方式,减少了阻塞的时间,如果要检测Slaveof的回复还需要一个单独的回调函数,这样一来程序复杂度与检测INFO回复差不多,②Slaveof 返回的是执行状态,INFO可能更加准确反映真实主从关系,虽然2者看上去好像都可以验证是否成功配置主从关系,但是INFO中是最终的状态,感觉更有保障一些吧。实际上Slaveof总是返回成功,无论ip地址是否合理,或者别的原因。Slaveof命令执行之后,并不能保证在回复之前与其新的Master连接,而是要等到下一个执行周期③要检测Slave节点与新的Master是否成功连接。这里面又有2个状态,当重新配置(RECONF)的Slave接收到INFO回复时,会修改状态为 SRI_RECONF_INPROG,再验证与Master是否连接成功,如果连接成功则再次修改状态为SRI_RECONF_DONE,至此Slave已经成功与新的Master成功连接。其他Slave也同理,会遍历slaves列表来依次处理。当全部(没有标记为主观下线,没有标记为晋升节点)Slave切换到追随新的Master后,修改原来Master状态为 SENTINEL_FAILOVER_STATE_UPDATE_CONFIG,然后接着执行下面的过程。
6. 最后,选择晋升Slave(SENTINEL_FAILOVER_STATE_UPDATE_CONFIG)
修改Seninel.masters.M1信息,关闭之前的连接,同时修改对应的IP/PORT 信息为新Master对应的信息。修改Sentinel.masters.M1.slaves 为其他Slave节点数据,并且加上之前故障的Master。然后就是到达指定执行周期之后重新创建这些连接,让一些服务恢复正常。
第④中情况说完之后,我们接着来分析其他几种情况,其故障检测原理基本相同。故障发现与处理过程不太相同。对于Slave与Sentinel的只会进行标记主观下线,不会标记客观下线,故障处理过程也要简单许多。也不必奇怪,因为Master才是真正对外提供服务的节点,其他角色的个别节点故障也并不会马上影响到客户端使用,但是一旦任意一个Master节点故障,则同时就会影响到客户端使用。
第③中情况:Slave 故障,被设置为了Master。有这么几种情况:其一,这个是晋升节点,这是上面说到情况,正常。其二,这个Slave原来的Master连接是否正常,如果正常则强制修改为原来的主从关系。其三,剩余情况则不处理。在正常的Sentinel架构中,客户端不会主动与Slave节点连接,所以即使Slave指向到新的未知的Master也不影响整体集群的可用性,因此没有处理其他情况。
据说,这种情况会触发故障转移,也就是说第④种处理流程相同。待续。。。。
第⑥种情况:Slave故障,追随了新的Master
这种情况,在上面介绍第④种情况的过程中有提到过。如果原来的Master健壮,则修改为原来的主从关系,追随原来的Mater节点。
只会标记为主观下线状态,当与第④种情况中同时发生时,会使用到这个状态获取可用的Slave。没发现有针对这种情况的解决处理。如果所有的Slave故障,可能会影响到数据的安全性,也会导致后续Master故障时,没有可用的Slave可以替换,所以当发生这种情况时,应该去人为介入去修复。
只会标记为主观下线状态,也并没有看到其他相关的处理。也没发现有针对这种情况的解决处理。但是如果大多数Sentinel节点故障时,会影响到Master的故障转移,所以当发生这种情况时,应人为介入及早修复。
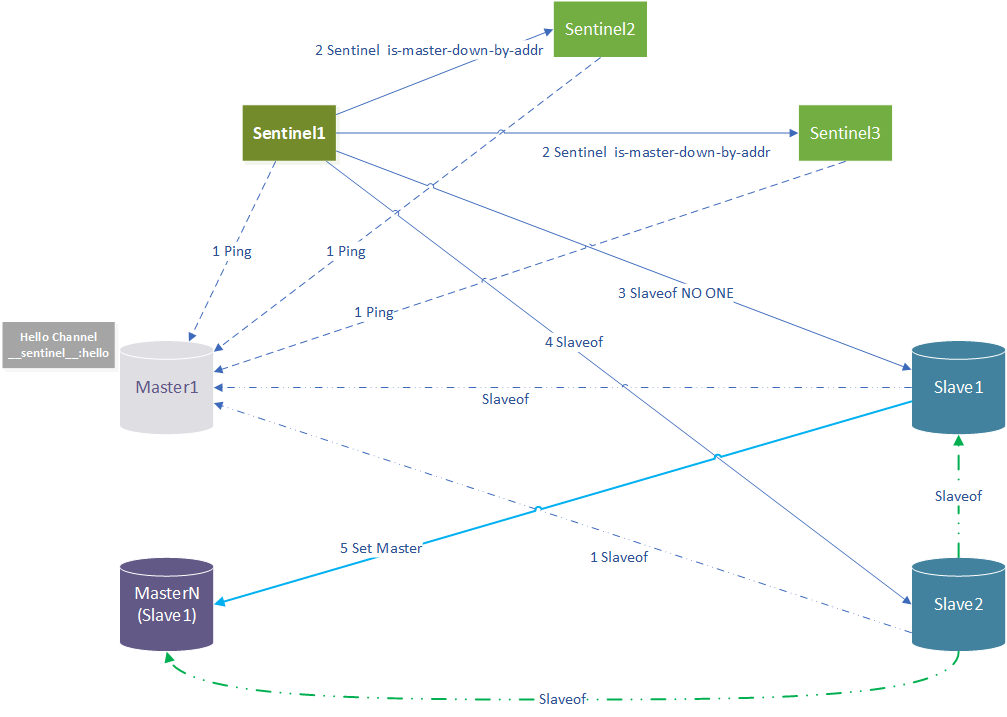
最后,放一个大致的流程图,中间有些简化。如果有任何问题,请指正!也可以查看 Redis Sentinel 通信原理
b( ̄▽ ̄)d
赞